CS50 Week 5: 数据结构(Data Structures)
复习
- 前几周我们学习如何在编程中构建基础的代码块
- 你在 C 语言中学到的所有知识将使你能够在 Python 等更高级的编程语言中实现这些构建模块
- 随着课程的进展,我们每周学习到的概念越来越有挑战,就像山越来越陡。本周,我们学习数据结构
- 目前为止,你已经学习了数组在内存中是如何组织数据的
- 今天继续讨论数据在内存中的组织方式以及随着学习知识的增长可能出现的设计可能性
课程官方笔记:https://cs50.harvard.edu/x/notes/5/
本周数据结构概览
| 数据结构 | 特点 | 时间复杂度(搜索) | 优点 | 缺点 |
|---|---|---|---|---|
| 数组 | 连续内存 | O(1) 随机访问 / O(log n) 二分搜索 | 快速访问、支持二分搜索 | 大小固定、扩容昂贵 |
| 链表 | 非连续内存 | O(n) | 动态大小、插入快 | 无法随机访问、额外内存 |
| 二叉搜索树 | 层级结构 | O(log n)(平衡时) | 动态 + 快速搜索 | 可能不平衡 |
| 哈希表 | 数组 + 链表 | O(1) 理想 / O(n) 最坏 | 极快的查找 | 碰撞问题、内存占用 |
| Trie | 数组构成的树 | O(1) | 常数时间搜索 | 内存消耗巨大 |
数据结构
- 数据结构本质是数据在内存中的组织形式
- 内存中数据组织的方式有很多种
- 抽象数据类型(ADT) 是我们能够概念化想象的数据类型。学习计算机科学时,从这些概念性数据结构入手往往很有帮助。掌握这些知识将有助于后续理解如何实现更具体的数据结构
队列(Queues)
- 队列是一种抽象数据结构的形式
- 队列具有特定属性,即遵循 FIFO(先进先出) 原则。你可以想象自己在游乐园排队等候游乐设施的情景:排队首位的人最先乘坐,队尾的人最后乘坐
- 队列关联着特定的操作:
- 入队(enqueue):元素加入队列(排到队尾)
- 出队(dequeue):元素离开队列(从队首移除)
在代码中,你可以将队列想象成如下形式:
const int CAPACITY = 50;
typedef struct
{
person people[CAPACITY];
int size;
} queue;
请注意,名为 people 的数组类型为 person。CAPACITY 表示队列的最大容量。整数 size 表示队列的实际占用空间,与最大容量无关。
栈(Stacks)
队列与栈形成鲜明对比。从根本上说,栈的特性与队列不同。具体而言,栈遵循 LIFO(后进先出) 原则。正如食堂里叠放餐盘的情景:最后放入堆叠中的餐盘,也是最先被取走的那个。
栈关联着特定的操作:
- push:将元素压入栈顶
- pop:从栈顶弹出元素
在代码中,你可以将栈想象成如下形式:
const int CAPACITY = 50;
typedef struct
{
person people[CAPACITY];
int size;
} stack;
你可能会想到上述代码存在局限性。由于该代码中数组容量始终是预先确定的,因此栈可能总是被过度分配。你可能会想到,在 5000 个栈空间中可能只使用其中一个位置。
如果我们的栈能够动态扩展——随着元素的添加而增长——那就太好了。
可变数组(Resizing Arrays)
回顾下 Week 2,我们介绍了第一种数据结构——数组。数组是一块连续内存,在内存中存储如下:

在内存中,其他程序、函数和变量也存储着其他值。其中许多可能是未使用的垃圾值——它们曾在某个时刻被利用过,但现在可供使用。

假设你想在数组中存储第四个值 4。需要做的是分配新的内存区域,并将旧数组移动到新区域。最初,这个新内存区域会被填充为垃圾值。
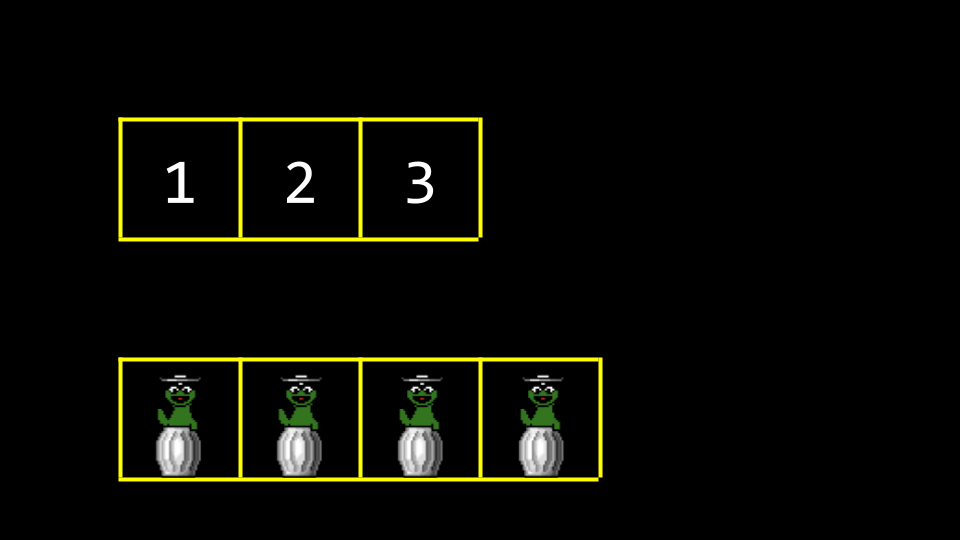
当值被添加到这个新的内存区域时,旧的垃圾值会被覆盖。
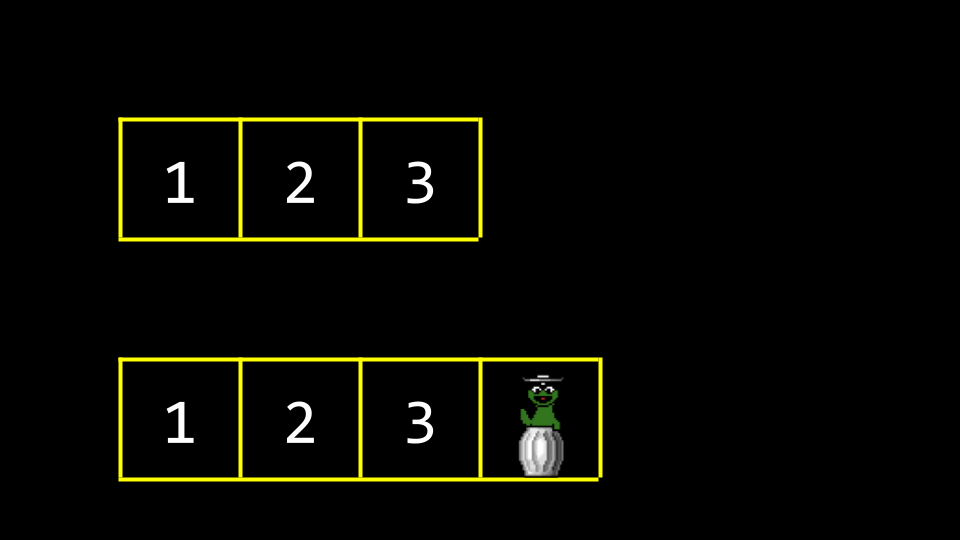
最终,所有旧的垃圾值都会被我们的新数据覆盖。
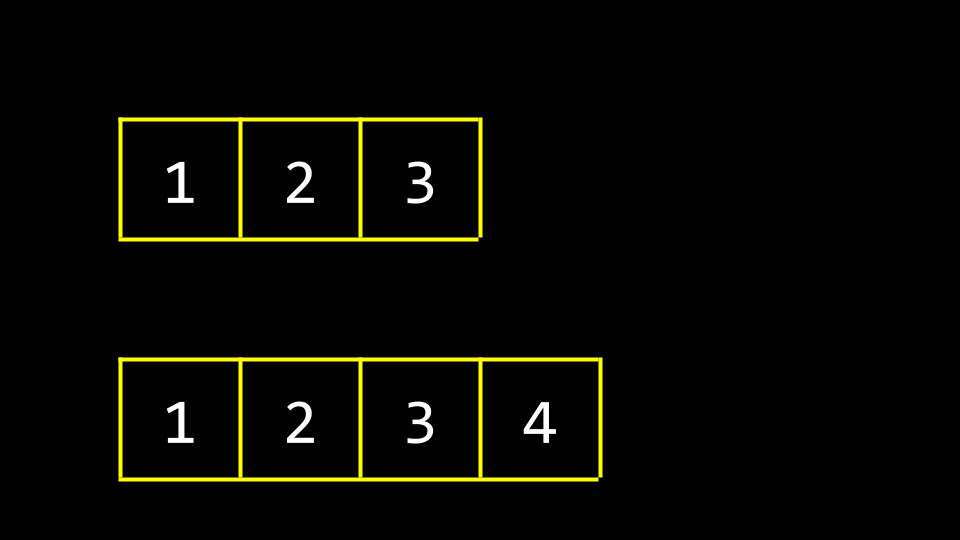
这种方法的一个缺点在于其设计欠佳:每次添加数字时,我们都必须逐元素复制数组。
数组(Arrays)
如果我们能把 4 放在内存的其他位置该多好?根据定义,这将不再是数组,因为 4 不再位于连续的内存区域。我们该如何连接内存中不同的位置呢?
如果你有数据结构的知识就知道链表可以实现。
在终端中输入 list.c 的代码:
// Implements a list of numbers with an array of fixed size
#include <stdio.h>
int main(void)
{
// List of size 3
int list[3];
// Initialize list with numbers
list[0] = 1;
list[1] = 2;
list[2] = 3;
// Print list
for (int i = 0; i < 3; i++)
{
printf("%i\n", list[i]);
}
}
请注意,以上内容与本课程前期所学内容高度相似。已预先为三个元素分配内存。
基于我们近期获得的知识,我们可以利用对指针的理解来改进此代码的设计。请按以下方式修改代码:
// Implements a list of numbers with an array of dynamic size
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
// List of size 3
int *list = malloc(3 * sizeof(int));
if (list == NULL)
{
return 1;
}
// Initialize list of size 3 with numbers
list[0] = 1;
list[1] = 2;
list[2] = 3;
// List of size 4
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL)
{
free(list);
return 1;
}
// Copy list of size 3 into list of size 4
for (int i = 0; i < 3; i++)
{
tmp[i] = list[i];
}
// Add number to list of size 4
tmp[3] = 4;
// Free list of size 3
free(list);
// Remember list of size 4
list = tmp;
// Print list
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
// Free list
free(list);
return 0;
}
请注意,这里创建了一个包含三个整数的列表。随后,三个内存地址被赋予值 1、2 和 3。接着创建了一个包含四个元素的列表。然后将第一个列表的内容复制到第二个列表中,并将数值 4 添加到临时列表中。由于列表指向的内存块不再被使用,通过调用 free(list) 命令将其释放。最后,编译器将指向 list 的指针指向 tmp 所指向的内存块。list 中元素被打印后释放指向的空间。另请注意文件 stdlib.h 的包含。
💡 提示:C 标准库提供了
realloc函数可以更方便地完成这个操作。
人们可能会倾向于为列表分配远超实际需求的内存,例如分配 30 个元素的空间,而实际只需 3 或 4 个。然而这种做法属于不良设计,因为它在系统资源尚未被消耗时就提前占用了资源。更何况,根本无法保证最终会需要超过 30 个元素的内存空间。
链表(Linked Lists)
在过去几周里,你已经学习了三个有用的基本概念:
- 结构体(struct):一种你可以自行定义的数据类型
- 点表示法(.):允许你访问该结构体内部的变量
*运算符:用于声明指针或解引用变量
今天,我们将介绍 -> 运算符。它是一个箭头。该运算符指向一个地址,并查看结构体内部。
链表是 C 语言中最强大的数据结构之一。它允许你包含位于内存不同区域的值,并且能够根据需要动态扩展或缩小列表。
你可以想象三个值存储在内存的三个不同区域中,如下所示:
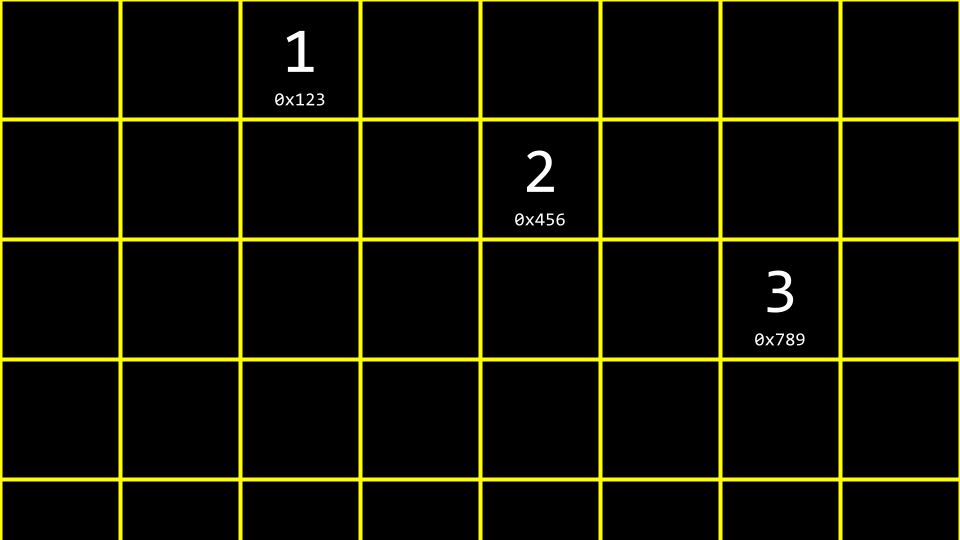
如何将这些值拼接成一个列表?我们可以将上图所示的数据想象为如下形式:
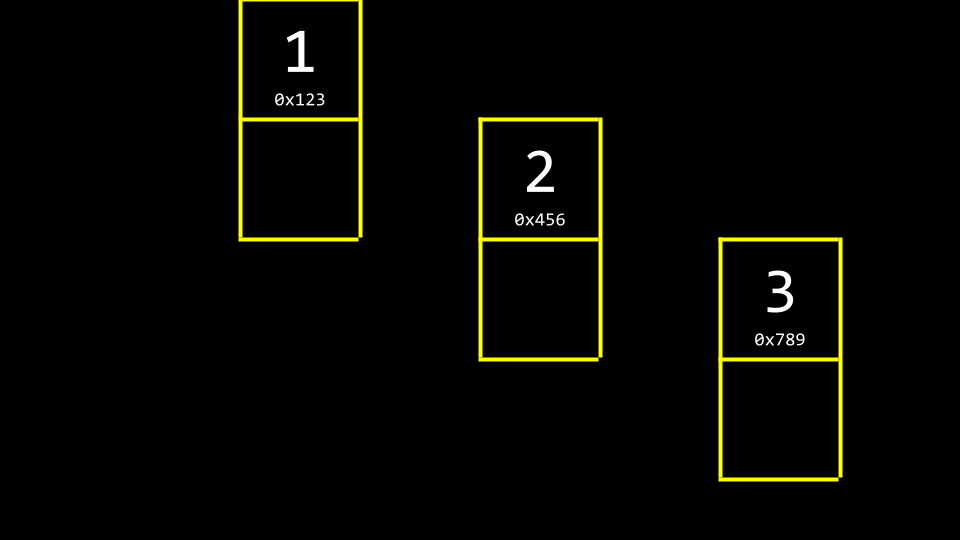
我们可以利用更多内存来跟踪下一个元素的位置,使用指针实现。
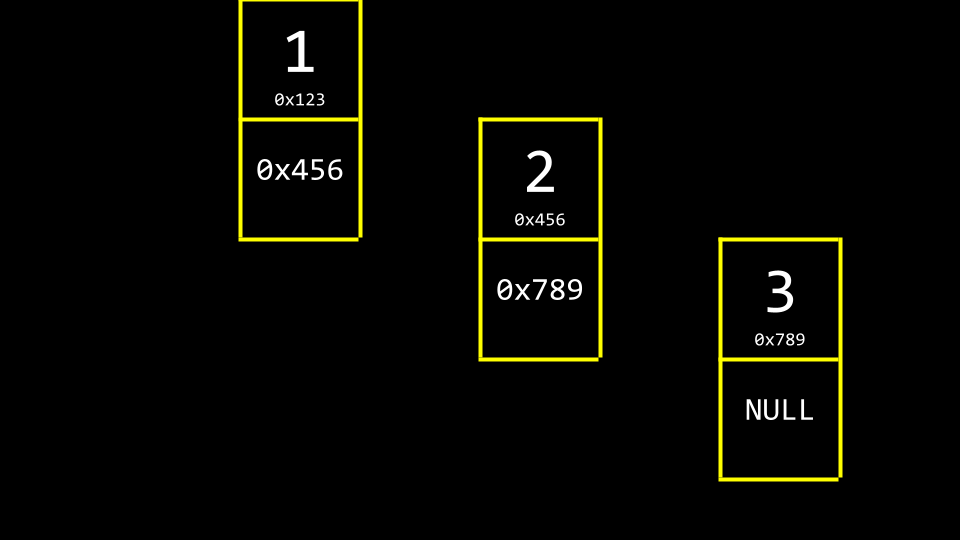
请注意,NULL 用于表示列表中没有后续项。
按惯例,我们会在内存中额外保留一个元素——一个指针,用于追踪列表中的第一个元素,该元素被称为链表的头节点(head)。
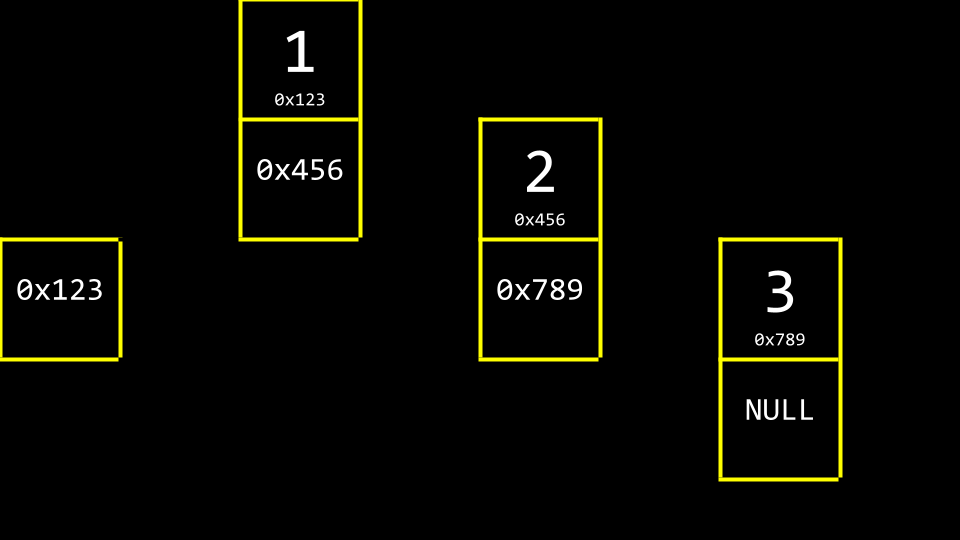
忽略内存地址后,该列表将呈现如下形式:
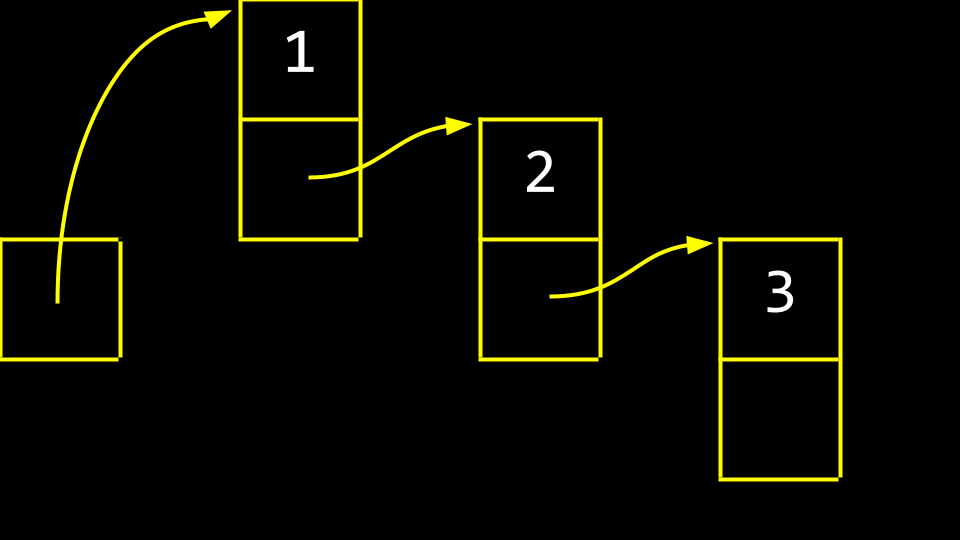
这些 box 被称为节点(node)。一个 node 包含一个元素和一个名为 next 的指针。在代码中,你可以将 node 想象成如下形式:
typedef struct node
{
int number;
struct node *next;
}
node;
请注意,node 包含的项是一个名为 number 的整数,一个指向名为 next 的节点的指针,该指针将指向内存中某个位置的另一个 node。
构建链表
我们可以重构 list.c 以使用链表:
// Start to build a linked list by prepending nodes
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
} node;
int main(void)
{
// Memory for numbers
node *list = NULL;
// Build list
for (int i = 0; i < 3; i++)
{
// Allocate node for number
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = get_int("Number: ");
n->next = NULL;
// Prepend node to list
n->next = list;
list = n;
}
return 0;
}
首先,定义一个 struct node。对于列表中的每个元素,通过 malloc 分配与 node 大小相符的内存空间。n->number(或 n 的 number 字段)被赋予整数值,n->next(或 n 的 next 字段)被赋予 NULL。随后,该 node 被放置在列表开头,存储于内存地址 list 处。这样,我们创建了一个有三个元素的链表。
链表构建过程图解
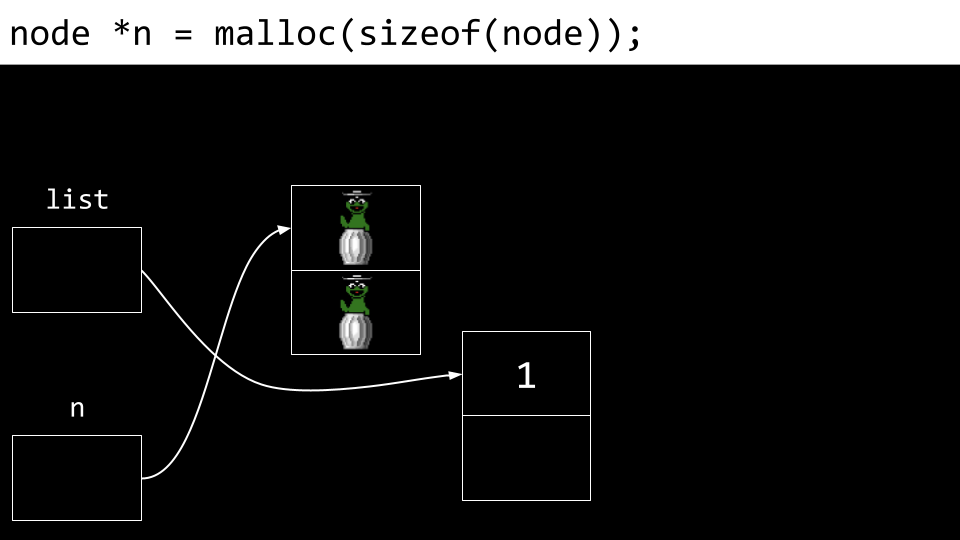
从概念上讲,我们可以想象创建链表的过程。首先声明 node *list,但此时它是一个垃圾值。

接下来,为 n(类型为 node*)在内存中申请一块内存。
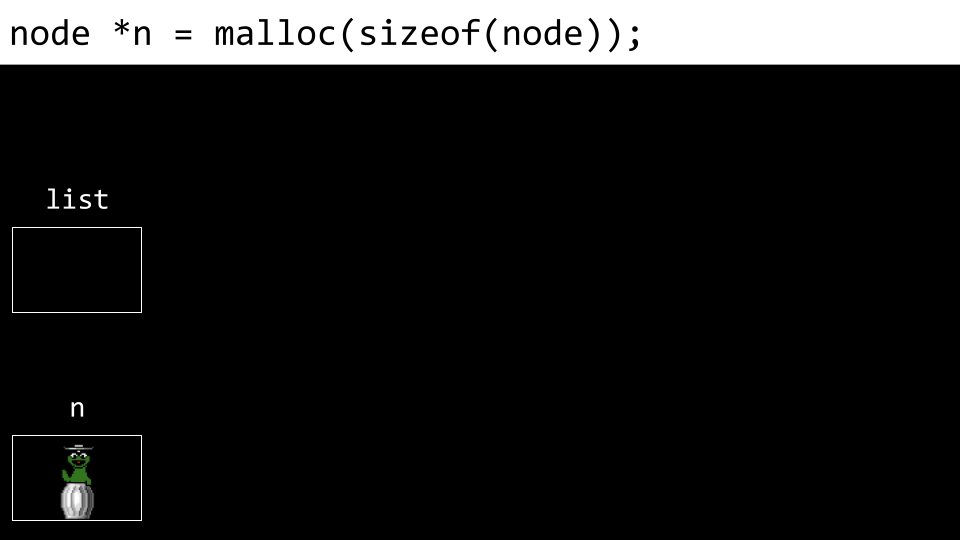
接下来,n 的 number 字段被赋值为 1。
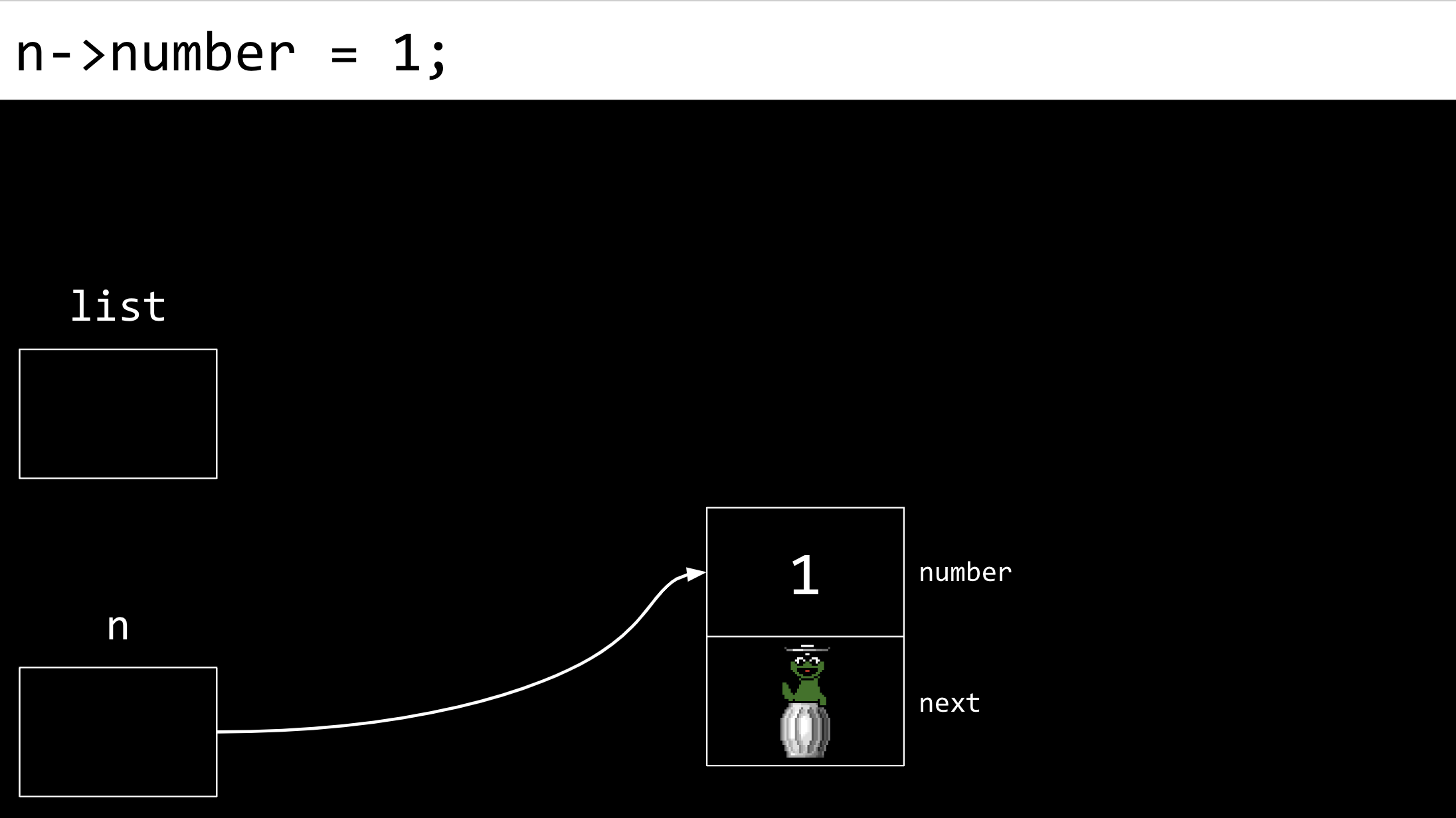
然后,n 的 next 字段被赋值为 NULL。
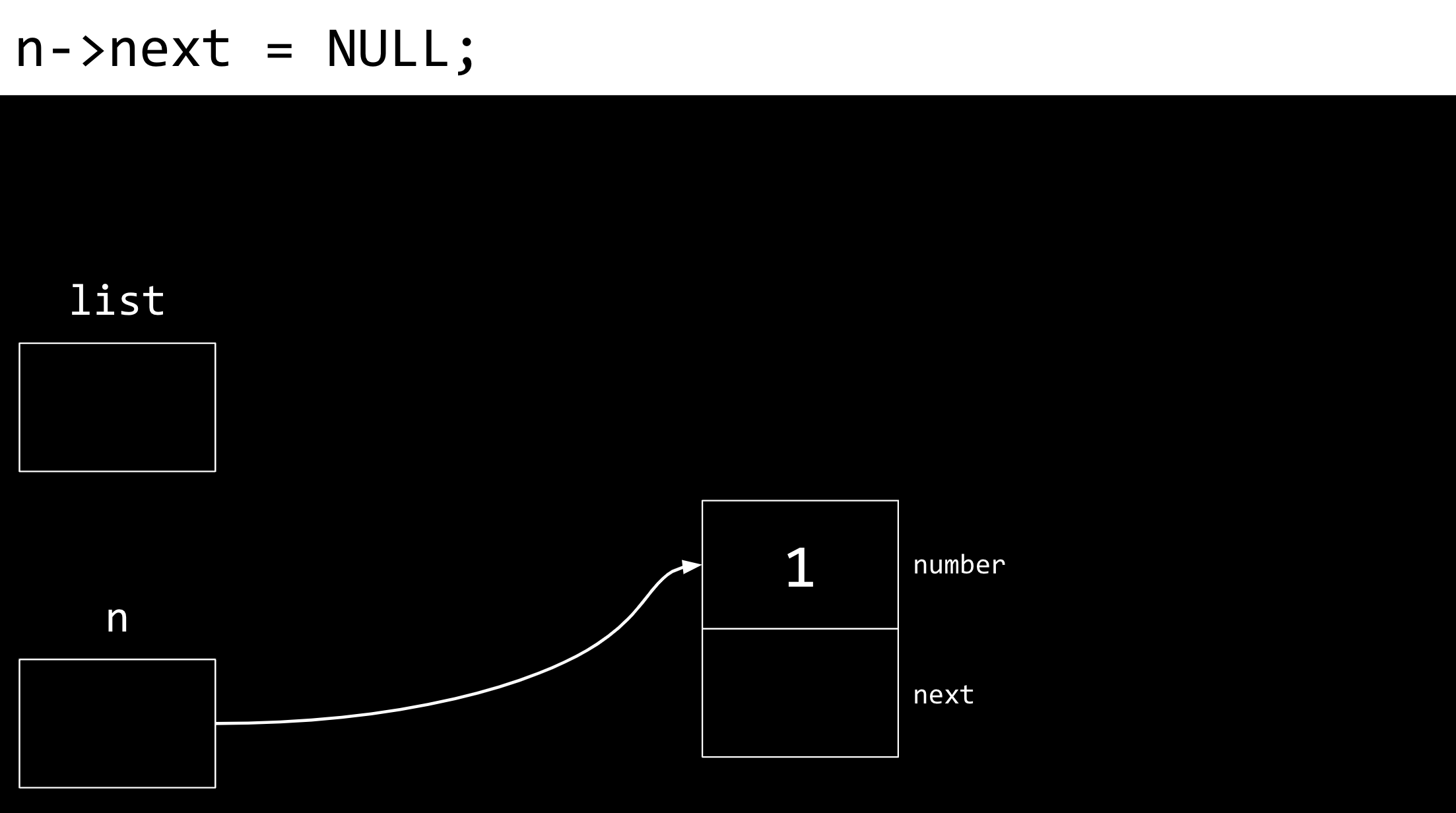
然后,list 指向 n 所指向的内存位置。n 和 list 现在指向同一个位置。
一个新节点被创建。其 number 和 next 字段均填入垃圾值。
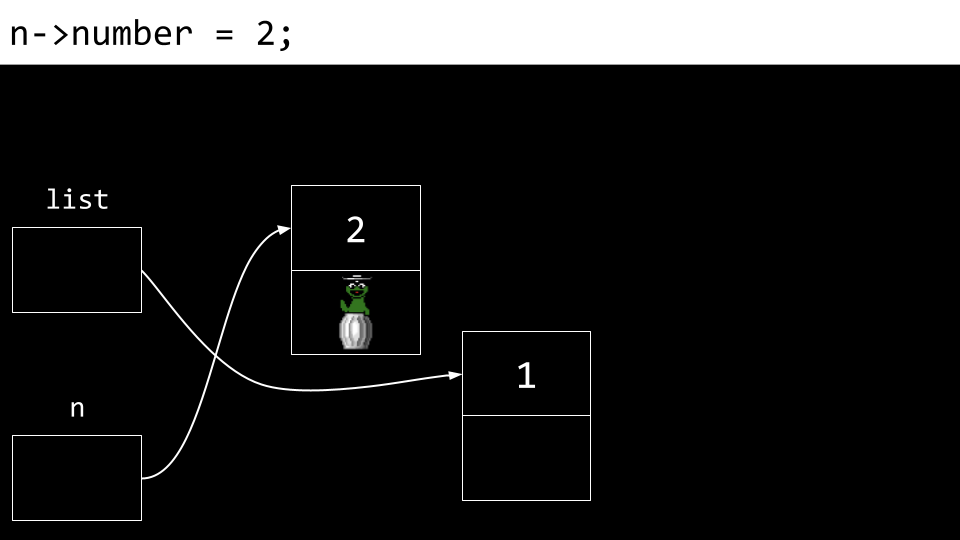
循环继续,n 的 number 更新为 2。
此外,next 字段也进行了更新。
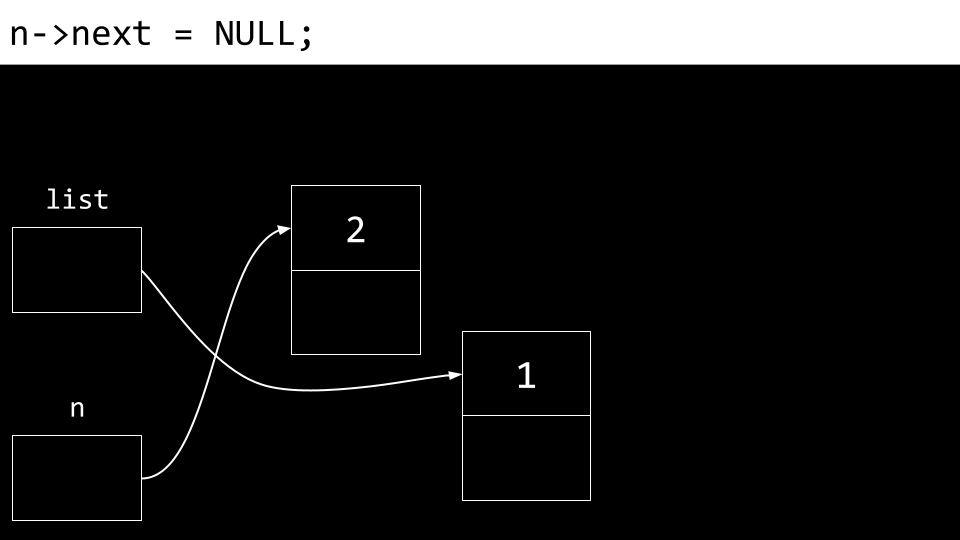
最重要的是,我们不希望与这些 node 中的任何一个断开连接,以免它们永远消失。因此,n 的 next 字段指向与 list 相同的内存位置。
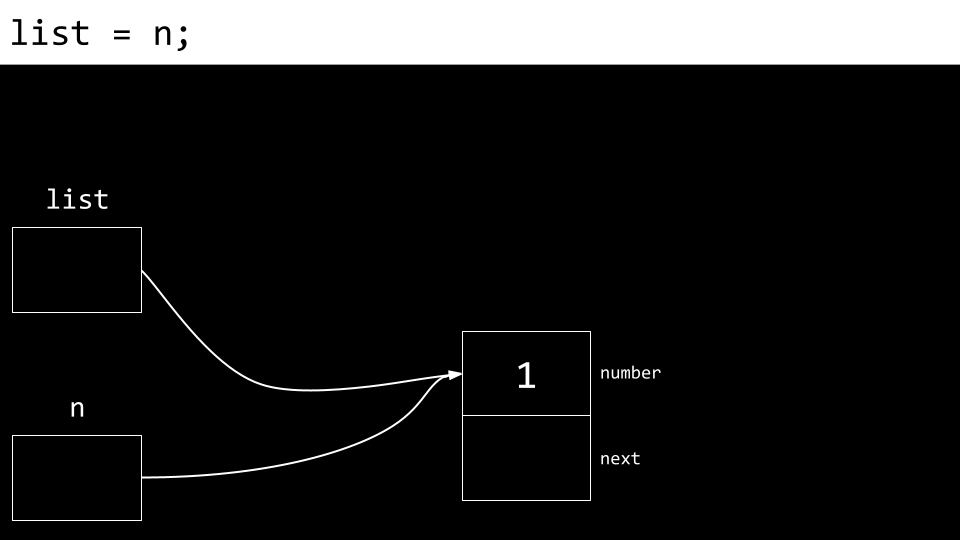
最后,list 被更新为指向 n。现在我们得到一个包含两个节点的链表。
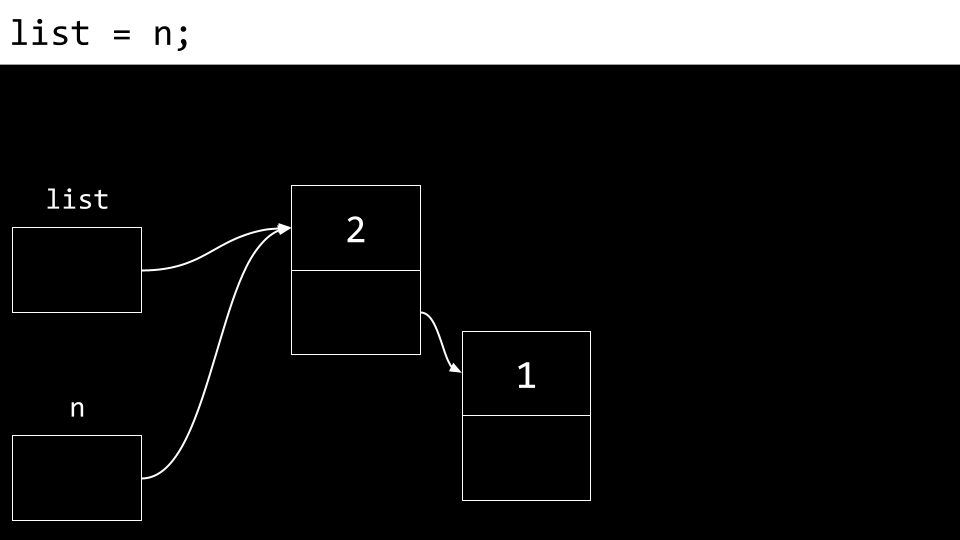
观察列表的示意图,我们发现最后添加的数字恰是列表中首次出现的数字。因此,若从第一个节点开始按顺序打印列表,其呈现的顺序将呈现逆序状态。
遍历链表
我们可以按正确顺序打印列表如下:
// Print nodes in a linked list with a while loop
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
} node;
int main(void)
{
// Memory for numbers
node *list = NULL;
// Build list
for (int i = 0; i < 3; i++)
{
// Allocate node for number
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = get_int("Number: ");
n->next = NULL;
// Prepend node to list
n->next = list;
list = n;
}
// Print numbers
node *ptr = list;
while (ptr != NULL)
{
printf("%i\n", ptr->number);
ptr = ptr->next;
}
return 0;
}
请注意,node *ptr = list 创建了一个临时变量,该变量指向与 list 指向相同的内存位置。while 循环会打印 ptr 节点指向的内容,然后将 ptr 更新为指向 list 中的下一个节点。
在此示例中,向 list 中插入元素的操作始终具有 O(1) 的复杂度,因为在 list 开头插入元素仅需极少步骤。
运行看下结果:
$ cd week5
week5/ $ make list
week5/ $ ./list
Number: 1
Number: 2
Number: 3
3
2
1
考虑到搜索此列表所需的时间复杂度,其呈 O(n) 级增长,因为最坏情况下必须遍历整个列表才能找到目标元素。向列表添加新元素的时间复杂度取决于添加位置,具体如下例所示。
链表不会存储在连续的内存块中。只要系统资源充足,它们可以无限扩展。然而其缺点在于,相较于数组,链表需要更多内存来维护结构——每个元素不仅要存储自身值,还需存储指向下一个节点的指针。此外,链表无法像数组那样直接索引定位,因为需要遍历前 n-1 个元素才能找到第 n 个元素的位置。因此上图所示的链表必须采用线性搜索,二分搜索在此类链表中不可行。
追加到链表末尾
另外,如代码所示,你也可以将数字放置在链表末尾:
// Appends numbers to a linked list
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
} node;
int main(void)
{
// Memory for numbers
node *list = NULL;
// Build list
for (int i = 0; i < 3; i++)
{
// Allocate node for number
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = get_int("Number: ");
n->next = NULL;
// If list is empty
if (list == NULL)
{
// This node is the whole list
list = n;
}
// If list has numbers already
else
{
// Iterate over nodes in list
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
// If at end of list
if (ptr->next == NULL)
{
// Append node
ptr->next = n;
break;
}
}
}
}
// Print numbers
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
printf("%i\n", ptr->number);
}
// Free memory
node *ptr = list;
while (ptr != NULL)
{
node *next = ptr->next;
free(ptr);
ptr = next;
}
return 0;
}
请注意这段代码如何遍历列表直至末尾。当追加元素(向列表末尾添加)时,我们的代码将以 O(n) 的复杂度运行,因为必须遍历整个列表才能添加最后一个元素。此外,请注意使用名为 next 的临时变量来追踪 ptr->next。
有序插入
另外,你可以在添加项时对列表进行排序:
// Implements a sorted linked list of numbers
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
} node;
int main(void)
{
// Memory for numbers
node *list = NULL;
// Build list
for (int i = 0; i < 3; i++)
{
// Allocate node for number
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = get_int("Number: ");
n->next = NULL;
// If list is empty
if (list == NULL)
{
list = n;
}
// If number belongs at beginning of list
else if (n->number < list->number)
{
n->next = list;
list = n;
}
// If number belongs later in list
else
{
// Iterate over nodes in list
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
// If at end of list
if (ptr->next == NULL)
{
// Append node
ptr->next = n;
break;
}
// If in middle of list
if (n->number < ptr->next->number)
{
n->next = ptr->next;
ptr->next = n;
break;
}
}
}
}
// Print numbers
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
printf("%i\n", ptr->number);
}
// Free memory
node *ptr = list;
while (ptr != NULL)
{
node *next = ptr->next;
free(ptr);
ptr = next;
}
return 0;
}
请注意该列表在构建过程中是如何排序的。若要按此特定顺序插入元素,每次插入操作仍需执行 O(n) 次操作——因为最坏情况下需遍历所有现有元素。
这段代码看似复杂。但请注意,借助指针与上述语法,我们能在内存的不同位置拼接数据。
链表操作详解(初学者指南)
对于第一次接触链表的人来说,上述两段代码理解上可能有点难度。下面我做个类比。
核心概念:头指针与游标指针
在链表中一定要建立起头指针(head) 和 游标指针(Iterator/Cursor) 的概念:
- 上面代码中的
list既是链表的名字,也是该链表的头指针 ptr就是游标指针,初始指向list头指针指向的位置
可以把上述两段代码想象成排队场景:
- 第一段代码(无序追加):类似食堂排队,不论谁来,直接站到队尾
- 第二段代码(有序插入):类似小学生按身高排队,新来的人需要根据身高插入队伍中,可能是队首,可能是队尾,也可能是中间
步骤详解
1. 共同的操作基础
// 造人(分配内存)
node *n = malloc(sizeof(node));
// 给这个人贴号码牌
n->number = get_int("Number: ");
// 这个人目前还没拉任何人的手
n->next = NULL;
2. 处理”空房间”(完全一致)
这是最简单的情况。房间里没人,你就是第一个。
if (list == NULL)
{
list = n; // 整个队伍就你一个人,list 指向你
}
3. 处理”排头”(分歧开始)
这里逻辑开始不同了。
代码 1(追加):它不在乎大小,只要队伍里有人,他就往后走,所以直接进入 else 去找队尾。
代码 2(排序):他必须先看一眼,我是不是比现在的队长(排头)还要矮?如果是,他要篡位,成为新队长。
// 只有排序代码需要这段
else if (n->number < list->number)
{
n->next = list; // 我(n)伸手拉住旧队长(list)
list = n; // 现在的队长变成我了
}
为什么代码 1 不需要这个?因为它不管大小,永远不插队,永远只往后面走。
4. 遍历寻找位置(核心难点)
我们先看两个代码在这里的根本目标有什么不同:
| 代码 | 目标 | 策略 |
|---|---|---|
| 代码 1(追加) | 找到最后一个人 | 只要后面还有人就继续走 |
| 代码 2(排序) | 找到一个缝隙 | 我比前面那个人大,比后面那个人小 |
代码 1:只找队尾(傻瓜式向前冲)
else
{
// ptr 是我们的侦察兵,从头开始走
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
// 唯一的判断:是不是走到队尾了?
if (ptr->next == NULL)
{
ptr->next = n; // 是队尾,那就把新来的 n 接在后面
break; // 任务完成,退出
}
}
}
代码 2:一边找队尾,一边看缝隙(带脑子走)
else
{
for (node *ptr = list; ptr != NULL; ptr = ptr->next)
{
// 情况A:走到队尾了(这部分和代码1一模一样!)
// 意思是我比所有人都高,只能站最后
if (ptr->next == NULL)
{
ptr->next = n;
break;
}
// 情况B:发现缝隙(这是代码2多出来的!)
// 我站在 ptr 的位置,看 ptr 的下一个人 (ptr->next)
// 如果新来的 n 比下一个人小,说明 n 应该插在 ptr 和 ptr->next 之间
if (n->number < ptr->next->number)
{
n->next = ptr->next; // 1. 新人拉住后面的人
ptr->next = n; // 2. 当前的人拉住新人
break; // 注意,这里顺序不能换,否则原来 ptr->next 变成一个孤点了
}
}
}
常见疑问解答
Q: “为什么要搞个
node *ptr = list?我直接用list往后移不行吗?”
千万不行! list 是你的命根子,它标记着队伍的头在哪里。如果你在 for 循环里写 list = list->next,你就把开头弄丢了,内存就泄漏了,整个链表也就找不回来了。
所以,无论是代码 1 还是代码 2,都需要:
node *ptr = list;(派一个分身/侦察兵ptr去干活,真身list留在原地不动)ptr = ptr->next(侦察兵一步步往前跳)
两段代码的关系总结
你可以把 代码 2(排序) 看作是 代码 1(追加) 的“威力加强版”:
| 插入位置 | 代码 1(追加) | 代码 2(排序) |
|---|---|---|
| 空链表 | ✅ | ✅ |
| 队头插入 | ❌ | ✅(新增 else if) |
| 队尾追加 | ✅ | ✅ |
| 中间插入 | ❌ | ✅(新增第二个 if) |
💡 给初学者的学习建议:先不要死记硬背
ptr->next->next这种东西。你就拿张纸,画三个方块。
- 如果要排在最后,你需要找到谁?(找到目前最后那个方块)
- 如果要插在中间,你需要找到谁?(找到插入位置的前一个方块)
代码 2 的精髓就是:因为是单向链表,为了插入到 X 前面,我必须停在 X 的前一个人那里操作。所以循环里一直在检查
ptr->next(下一个人)的值。
树(Trees)
数组提供连续的内存空间,可实现快速搜索。数组还提供了进行二分搜索的可能性。
我们能否将数组和链表的优势结合起来?
二叉搜索树(Binary Search Tree, BST) 是另一种数据结构,能更高效地存储数据以便搜索和检索。
你可以想象一个排序的数字序列:
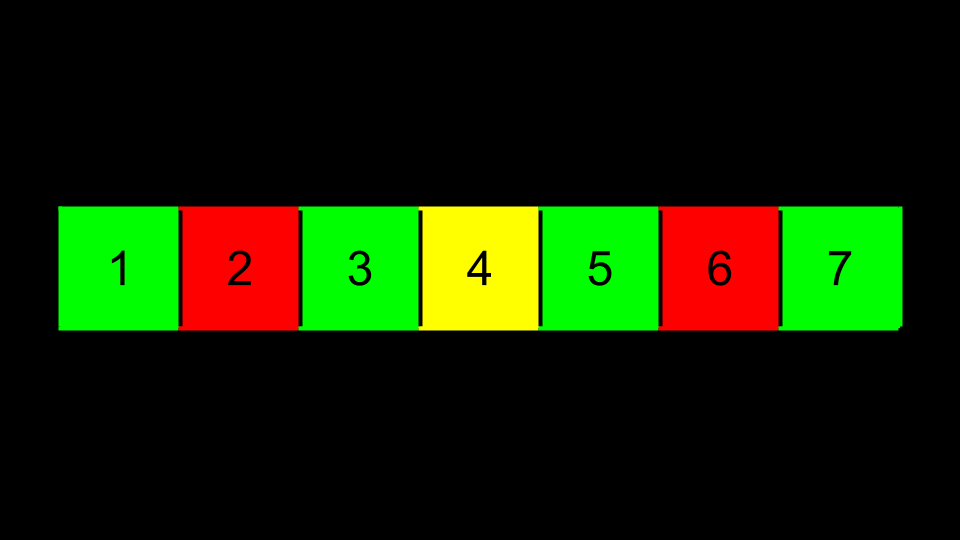
试想中心元素成为树的顶点。小于该元素值的元素置于左侧,大于该元素值的元素则位于右侧。
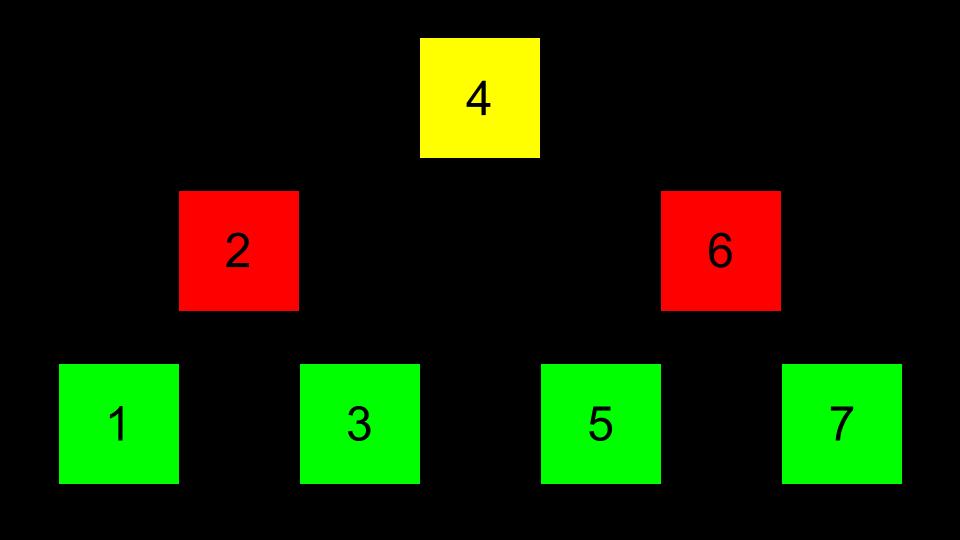
指针可用于指向内存中每个区域的正确位置,从而使这些节点能够相互连接。
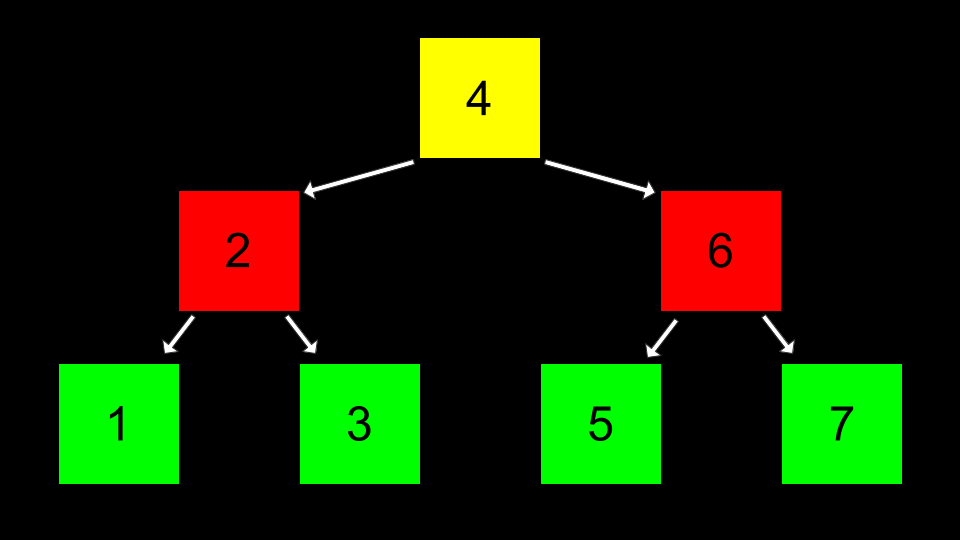
可以用以下代码实现:
// Implements a list of numbers as a binary search tree
#include <stdio.h>
#include <stdlib.h>
// Represents a node
typedef struct node
{
int number;
struct node *left;
struct node *right;
}
node;
void free_tree(node *root);
void print_tree(node *root);
int main(void)
{
// Tree of size 0
node *tree = NULL;
// Add number to list
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 2;
n->left = NULL;
n->right = NULL;
tree = n;
// Add number to list
n = malloc(sizeof(node));
if (n == NULL)
{
free_tree(tree);
return 1;
}
n->number = 1;
n->left = NULL;
n->right = NULL;
tree->left = n;
// Add number to list
n = malloc(sizeof(node));
if (n == NULL)
{
free_tree(tree);
return 1;
}
n->number = 3;
n->left = NULL;
n->right = NULL;
tree->right = n;
// Print tree
print_tree(tree);
// Free tree
free_tree(tree);
return 0;
}
void free_tree(node *root)
{
if (root == NULL)
{
return;
}
free_tree(root->left);
free_tree(root->right);
free(root);
}
void print_tree(node *root)
{
if (root == NULL)
{
return;
}
print_tree(root->left);
printf("%i\n", root->number);
print_tree(root->right);
}
上述代码先构建了一个三个节点的二叉搜索树(BST),树的根节点的值为 2,左子树的值为 1,右子树的值为 3。然后打印出树的值,最后释放树。
请注意,此搜索函数首先定位到树的位置,随后通过递归方式搜索数字。free_tree 函数递归释放树结构,print_tree 函数则递归打印树结构(中序遍历)。
相较于数组,此类树结构具备动态扩展特性,可随需求自由增长或缩减。
此外,当树结构保持平衡时,其搜索时间复杂度为 O(log n)。
字典(Dictionaries)
字典是另一种数据结构。
字典如同实体词典般包含词条与释义,具有键值对(key-value) 的特性。
算法时间复杂度的终极目标是 O(1) 或常数时间——即实现瞬时访问。
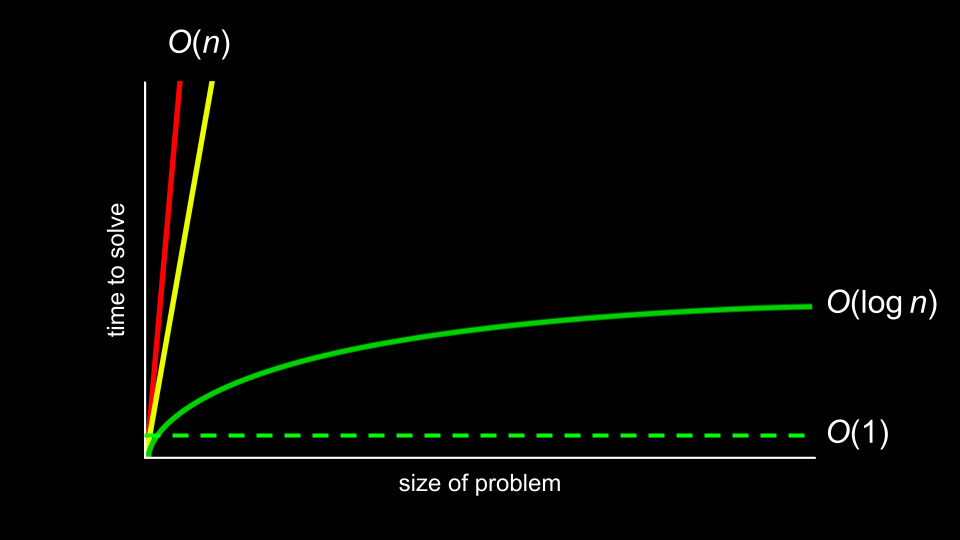
字典通过哈希技术能够实现这种访问速度。
哈希和哈希表(Hashing and Hash Tables)
哈希算法的核心思想是:将一个值输入后,输出一个值,该值可作为后续查找该值的快捷方式。
例如,对 “apple” 进行哈希处理可能得到值 1,而 “berry” 可能得到值 2。因此,查找 “apple” 只需询问哈希算法 “apple” 存储的位置即可。虽然将所有 “a” 开头的词放入一个桶、所有 “b” 开头的词放入另一个桶的设计并不理想,但这种桶化(bucketizing) 哈希值的概念展示了其应用方式:哈希值可作为查找对应值的捷径。
哈希函数是一种将较大值缩减为较小且可预测值的算法。通常,该函数接收要添加到哈希表中的项,并返回一个整数,该整数代表该项应放置的数组索引。
哈希表是数组与链表的绝妙结合。在代码实现中,哈希表是一个指向节点的指针数组。
哈希表可理解为如下结构:

请注意,这是一个数组,其中每个元素都赋予字母表中的一个字母值。
然后,在数组的每个位置,使用链表来追踪存储在此处的每个值:

当向哈希表添加值时,若哈希位置已存在数据,即发生碰撞(collision)。在上例中,碰撞项会被简单地追加到列表末尾。
通过优化哈希表设计和哈希算法可减少碰撞。可设想对上述方案进行如下改进:

考虑以下哈希算法的示例:
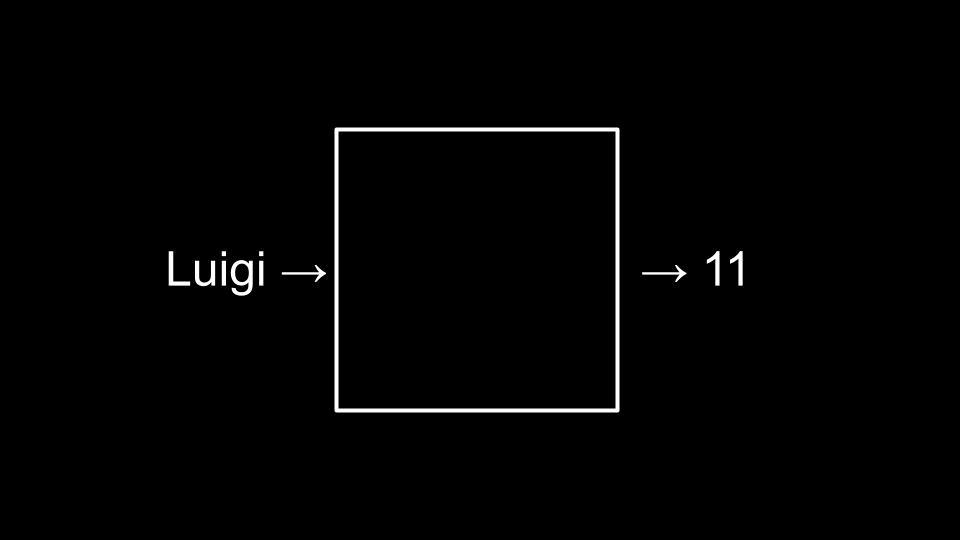
这可以在代码中实现如下:
#include <ctype.h>
unsigned int hash(const char *word)
{
return toupper(word[0]) - 'A';
}
请注意哈希函数返回的是 toupper(word[0]) - 'A' 的值。
作为程序员,你需要权衡两种选择的利弊:使用更多内存构建大型哈希表以缩短搜索时间,还是使用较少内存但可能延长搜索时间。
这种数据结构的时间复杂度是 O(n)(最坏情况),但理想情况下可以接近 O(1)。
字典树(Tries)
Trie(又称前缀树、字典树)是另一种数据结构形式。Trie 是数组构成的树。
Trie 始终支持常数时间搜索。
Trie 的一个缺点是往往占用大量内存。注意仅存储 “Toad” 就需要 26 × 4 = 104 个节点!
“Toad” 将按以下方式存储:
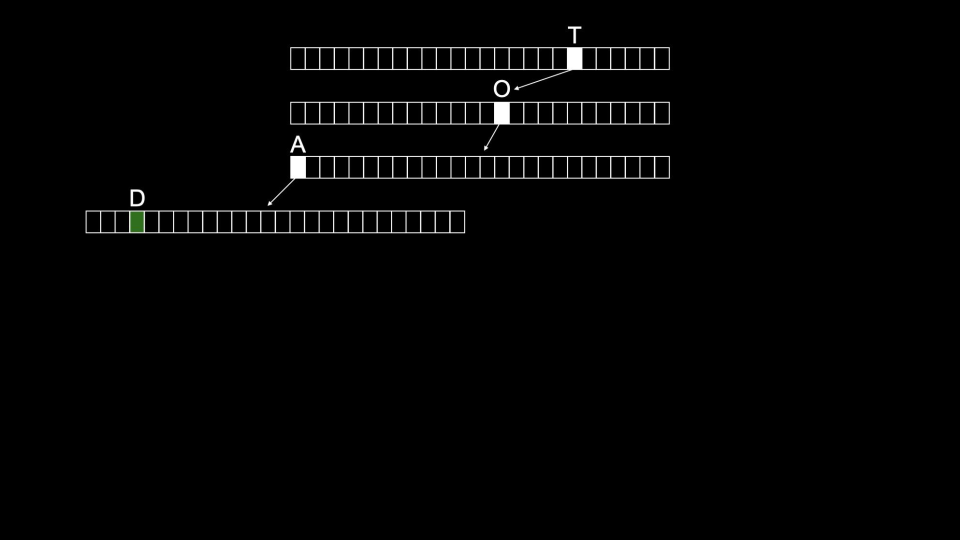
“Tom” 将按以下方式存储:
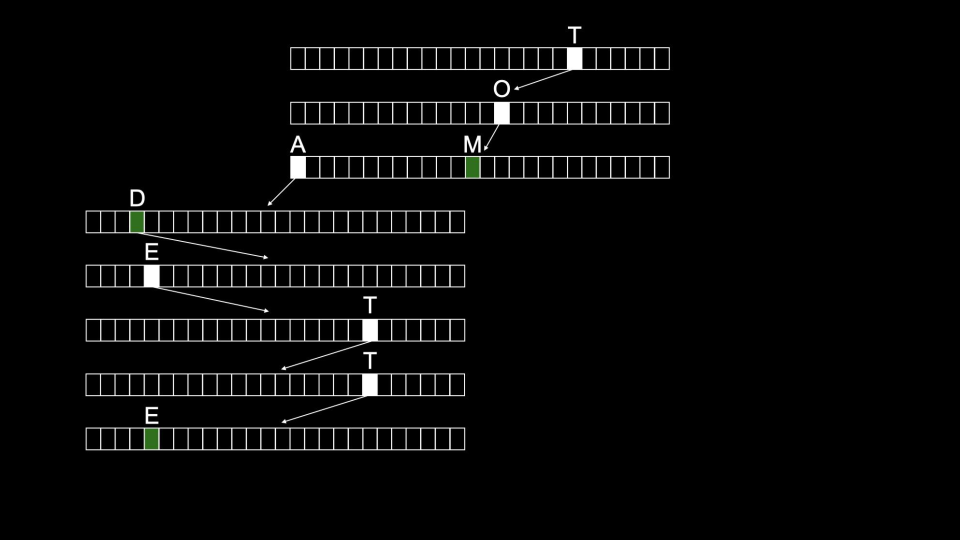
该结构提供 O(1) 的搜索时间(相对于数据量,只与键的长度有关)。
其缺点在于使用时需要消耗大量资源。
💡 更多关于字典树的知识在后续数据结构与算法课程中还会讲到,感兴趣的也可以提前了解。
总结
在本节课中,你学习了如何使用指针构建新的数据结构。具体而言,我们深入探讨了:
| 数据结构 | 关键特性 |
|---|---|
| 栈与队列 | LIFO vs FIFO |
| 可变数组 | 动态扩容但代价高 |
| 链表 | 动态、灵活,但无法随机访问 |
| 二叉搜索树 | 结合数组和链表优点,O(log n) 搜索 |
| 哈希表 | 理想情况 O(1),需处理碰撞 |
| Trie | 常数时间搜索,内存消耗大 |
下次见! 🚀
参考资料: