CS50 Week 3: 算法(Algorithms)
本周主题:
- 搜索算法:线性搜索(Linear Search)、二分查找(Binary Search)
- 排序算法:冒泡排序(Bubble Sort)、选择排序(Selection Sort)、归并排序(Merge Sort)
- 算法复杂度:大O表示法(𝑂)、Ω、Θ
- 递归(Recursion)
引言
在Week 0中,我们介绍了算法的概念:一个接收输入并产生输出的”黑箱”。
本周,我们将:
- 通过伪代码(pseudocode)深入理解算法
- 将伪代码转换为真正的C代码
- 探讨算法的效率问题
- 学习如何衡量和比较不同算法的性能
为什么算法效率很重要?
回顾之前介绍算法时展示的图表:
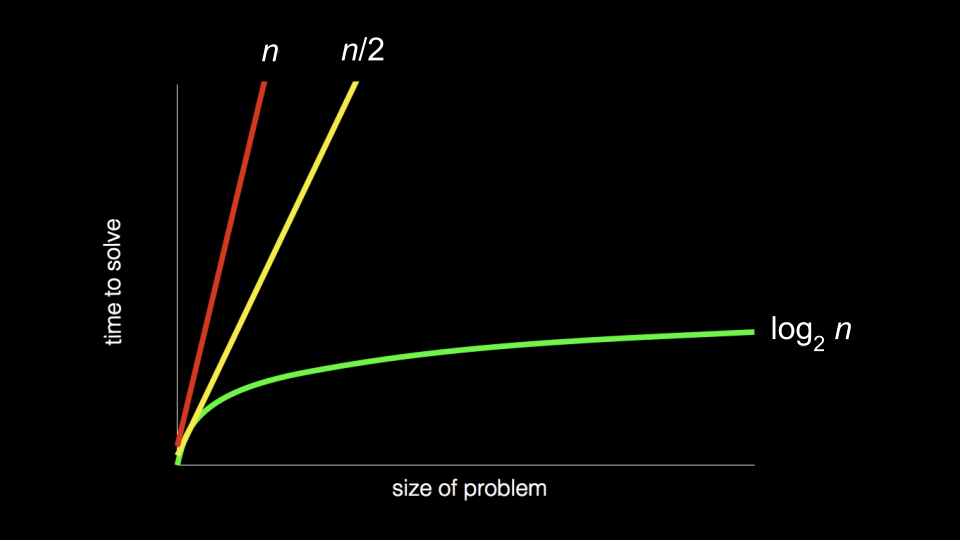
关键问题:算法处理问题的方式如何决定解决问题所需的时间?
- 对于小规模数据,算法效率差异可能不明显
- 但对于大规模数据(如百万级、亿级),效率差异可能是秒级 vs 天级!
- 算法的设计可以不断提升效率,但总有理论上的极限
今天,我们将聚焦于:
- 算法设计:如何设计高效的算法
- 效率衡量:如何用数学方法比较算法性能
线性搜索(Linear Search)
问题场景
回顾上周,我们学习了数组的概念——内存中连续存储的数据块。
可以将数组想象成一排储物柜:
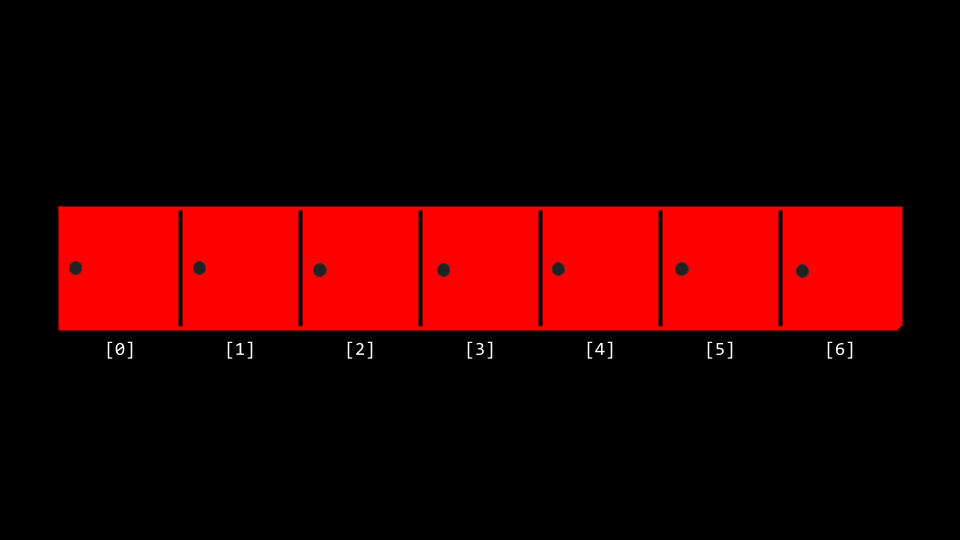
数组索引:
- 最左端是索引
0(数组的起始位置) - 最右端是索引
6(如果有7个元素)
搜索问题
基本问题:如何判断数字 50 是否存在于某个数组中?
解决方案:计算机必须逐个检查每个位置的数据,这个过程称为搜索(searching)。
搜索的定义:在数据集合中查找特定的数字、字符、字符串或其他项目的过程。
线性搜索算法
我们可以设计一个算法:
- 输入:数组和要查找的目标值
- 输出:
true(找到)或false(未找到)
伪代码版本1(人类语言)
For each door from left to right
If 50 is behind door
Return true
Return false
说明:
- 从左到右检查每个”门”(储物柜)
- 如果找到50,立即返回
true - 如果检查完所有门都没找到,返回
false
这种人类可读的指令描述称为伪代码(pseudocode)。
伪代码版本2(更接近代码)
For i from 0 to n-1
If 50 is behind doors[i]
Return true
Return false
改进:
- 使用循环变量
i遍历索引0到n-1 - 使用数组表示法
doors[i] - 更接近实际编程语言的结构
虽然这仍然是伪代码,但已经非常接近最终的C代码了。
二分查找(Binary Search)
更聪明的搜索方式
二分查找是另一种搜索算法,比线性搜索更高效。
前提条件:数组必须已经排序(从小到大或从大到小)。
核心思想
就像在电话簿中查找名字:
- 翻到中间
- 如果要找的名字在当前页之前,就在左半部分继续查找
- 如果在当前页之后,就在右半部分继续查找
- 重复这个过程,每次将搜索范围缩小一半
伪代码版本1
If no doors left
Return false
If 50 is behind middle door
Return true
Else if 50 < middle door
Search left half
Else if 50 > middle door
Search right half
关键步骤:
- 检查中间位置
- 根据比较结果,丢弃一半的数据
- 在剩余的一半中重复这个过程
伪代码版本2(更具体)
If no doors left
Return false
If 50 is behind doors[middle]
Return true
Else if 50 < doors[middle]
Search doors[0] through doors[middle - 1]
Else if 50 > doors[middle]
Search doors[middle + 1] through doors[n - 1]
说明:
doors[middle]- 数组中间位置的元素doors[0] through doors[middle - 1]- 左半部分doors[middle + 1] through doors[n - 1]- 右半部分
为什么二分查找更快?
线性搜索:最坏情况需要检查 n 个元素 二分查找:每次排除一半,最坏情况只需检查 log₂(n) 次
示例:在1000个元素中查找
- 线性搜索:最多 1000 次
- 二分查找:最多 10 次(因为 2¹⁰ = 1024)
运行时间与算法复杂度
什么是运行时间?
运行时间(Running Time)是指算法解决问题所需的时间。
我们需要一种方法来比较不同算法的效率,这就是大O表示法(Big O Notation)。
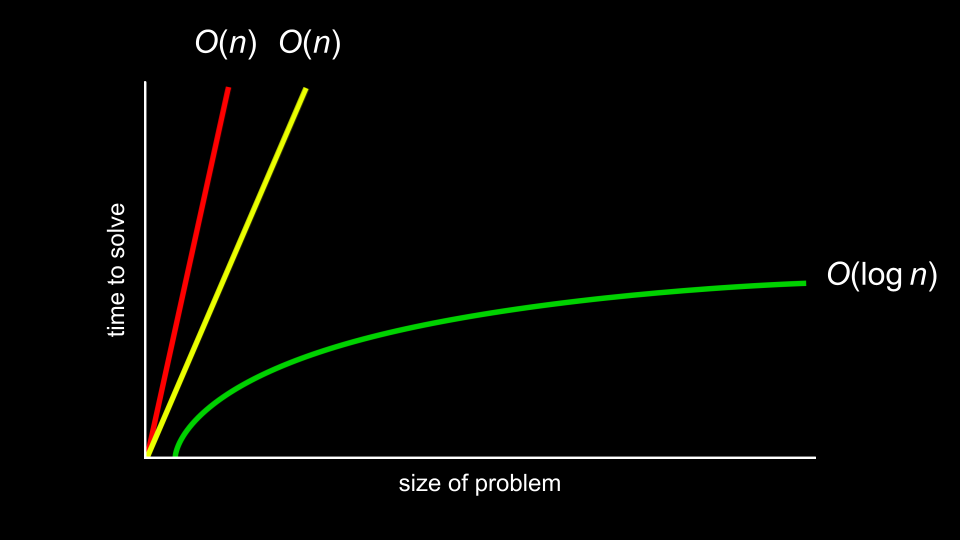
大O表示法(Big O)
计算机科学家在讨论算法效率时,不会精确计算具体需要多少毫秒,而是关注增长趋势。
关键问题:当数据规模 n 增大时,运行时间如何增长?
常见的时间复杂度(从慢到快)
| 复杂度 | 名称 | 说明 | 示例 |
|---|---|---|---|
| 𝑂(n²) | 平方级 | 非常慢 | 简单的排序算法 |
| 𝑂(n log n) | 线性对数级 | 较快 | 高效的排序算法 |
| 𝑂(n) | 线性级 | 中等 | 线性搜索 |
| 𝑂(log n) | 对数级 | 很快 | 二分查找 |
| 𝑂(1) | 常数级 | 最快 | 数组索引访问 |
图表中的曲线:
- 红色/黄色直线:𝑂(n) - 线性增长
- 绿色曲线:𝑂(log n) - 增长缓慢
具体示例
线性搜索:𝑂(n)
- 最坏情况:需要检查所有 n 个元素
- 随着数据量翻倍,时间也翻倍
二分查找:𝑂(log n)
- 最坏情况:每次减半,需要 log₂(n) 步
- 数据量翻倍,只多检查 1 次!
其他重要符号
Ω(Omega)- 最好情况
表示算法的下界(best case)。
示例:
- 线性搜索的最好情况:Ω(1) - 第一个就找到
- 二分查找的最好情况:Ω(1) - 中间位置就是目标
Θ(Theta)- 严格界限
当最好情况和最坏情况相同时使用。
示例:
- 归并排序:Θ(n log n) - 无论如何都需要这么多时间
对比表格
| 算法 | 最好情况 (Ω) | 最坏情况 (𝑂) |
|---|---|---|
| 线性搜索 | Ω(1) | 𝑂(n) |
| 二分查找 | Ω(1) | 𝑂(log n) |
| 归并排序 | Ω(n log n) | 𝑂(n log n) |
为什么这很重要?
示例对比(在100万个元素中搜索):
- 𝑂(1):1 次操作
- 𝑂(log n):约 20 次操作
- 𝑂(n):1,000,000 次操作
- 𝑂(n²):1,000,000,000,000 次操作
差距巨大!这就是为什么我们需要学习高效的算法。
搜索算法的C语言实现
整数数组的线性搜索
// 在整数数组中进行线性搜索
#include <stdio.h>
#include <cs50.h>
int main(void)
{
// 定义并初始化整数数组
int numbers[] = {20, 500, 10, 5, 100, 1, 50};
// 获取要搜索的数字
int target = get_int("Number: ");
// 线性搜索:遍历数组
for (int i = 0; i < 7; i++)
{
if (numbers[i] == target)
{
printf("Found\n");
return 0; // 找到了,返回成功状态
}
}
// 遍历完整个数组都没找到
printf("Not found\n");
return 1; // 返回错误状态
}
代码详解:
- 数组初始化:
int numbers[] = {20, 500, 10, 5, 100, 1, 50};这是数组的初始化语法,直接在定义时给每个元素赋值
- 线性搜索循环:
for (int i = 0; i < 7; i++)从索引0到6,逐个检查
- 返回值:
return 0- 找到目标,程序正常退出return 1- 未找到目标,程序异常退出
至此,我们用C语言实现了线性搜索!
字符串数组的线性搜索
如果需要在字符串数组中搜索,代码需要做些调整:
// 在字符串数组中进行线性搜索
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void)
{
// 字符串数组(大富翁游戏的棋子)
string strings[] = {"battleship", "boot", "cannon", "iron", "thimble", "top hat"};
// 获取要搜索的字符串
string target = get_string("String: ");
// 遍历字符串数组
for (int i = 0; i < 6; i++)
{
// 使用 strcmp 比较字符串
if (strcmp(strings[i], target) == 0)
{
printf("Found\n");
return 0;
}
}
printf("Not found\n");
return 1;
}
重要变化:
- 不能用
==比较字符串:// 错误! if (strings[i] == target) // 正确! if (strcmp(strings[i], target) == 0)原因:
==比较的是字符串的内存地址,而不是内容 - strcmp 函数:
- 来自
string.h库 - 返回值:
0- 两个字符串相同< 0- 第一个字符串小于第二个> 0- 第一个字符串大于第二个
- 来自
- 硬编码的问题:
i < 6是硬编码的数组长度- 更好的做法:使用常量或计算数组大小
const int SIZE = 6; for (int i = 0; i < SIZE; i++)
常见错误:
- 如果写成
i < 7,会访问数组越界,导致段错误(Segmentation Fault) - 段错误 = 程序试图访问不属于它的内存
参考资料:更多关于 strcmp 的信息,请查阅 CS50 Manual - strcmp
电话簿示例(phonebook.c)
问题引入
前面的例子中,数字和字符串是分开的。现实中,我们常需要将相关数据组合在一起,比如电话簿:
- 姓名和电话号码应该是关联的
- 如何在C语言中表示这种关联?
让我们先看一个不太好的实现方式:
// 使用两个平行数组的电话簿
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
// 两个平行数组
string names[] = {"Yuliia", "David", "John"};
string numbers[] = {"+1-617-495-1000", "+1-617-495-1000", "+1-949-468-2750"};
// 搜索姓名
string name = get_string("Name: ");
for (int i = 0; i < 3; i++)
{
if (strcmp(names[i], name) == 0)
{
printf("Found %s\n", numbers[i]);
return 0;
}
}
printf("Not found\n");
return 1;
}
数据结构:
names[0]= “Yuliia” →numbers[0]= “+1-617-495-1000”names[1]= “David” →numbers[1]= “+1-617-495-1000”names[2]= “John” →numbers[2]= “+1-949-468-2750”
工作原理:
- 在
names数组中查找姓名 - 找到后,使用相同的索引
i从numbers数组获取电话号码
这种方法的问题
- 关联性不明确:
- 姓名和号码分别存储在两个数组中
- 依赖索引对应关系,容易出错
- 维护困难:
- 添加新联系人时,必须同时更新两个数组
- 删除时也要确保两个数组同步
- 代码不够直观:
- 看代码不能直观地看出姓名和号码的关联
更好的方案:创建一个自定义数据类型,将姓名和号码”捆绑”在一起!
结构体(Structs)
创建自定义数据类型
C语言允许我们通过结构体(struct)创建自己的数据类型!
想法:创建一个叫 person 的新类型,它包含:
- 姓名(name)
- 电话号码(number)
定义结构体
typedef struct
{
string name;
string number;
} person;
语法详解:
typedef struct- 定义一个新的数据类型{ ... }- 结构体的成员(字段)person- 新类型的名字
效果:现在 person 就像 int、string 一样,成为了一个数据类型!
使用结构体改进电话簿
// 使用结构体的电话簿
#include <cs50.h>
#include <stdio.h>
#include <string.h>
// 定义 person 结构体
typedef struct
{
string name;
string number;
} person;
int main(void)
{
// 创建 person 类型的数组
person people[3];
// 为每个 person 赋值
people[0].name = "Yuliia";
people[0].number = "+1-617-495-1000";
people[1].name = "David";
people[1].number = "+1-617-495-1000";
people[2].name = "John";
people[2].number = "+1-949-468-2750";
// 搜索姓名
string name = get_string("Name: ");
for (int i = 0; i < 3; i++)
{
// 使用点操作符访问结构体成员
if (strcmp(people[i].name, name) == 0)
{
printf("Found %s\n", people[i].number);
return 0;
}
}
printf("Not found\n");
return 1;
}
代码详解:
- 定义结构体:
typedef struct { string name; string number; } person;创建了一个新类型
person,包含两个字符串成员 - 创建结构体数组:
person people[3];创建了一个包含3个
person元素的数组 - 访问结构体成员(使用点操作符
.):people[0].name = "Yuliia"; // 设置第1个人的姓名 people[0].number = "+1-617..."; // 设置第1个人的号码 - 在循环中使用:
people[i].name // 访问第 i 个人的姓名 people[i].number // 访问第 i 个人的号码
结构体的优势
✅ 数据关联清晰:姓名和号码被”捆绑”在一个 person 对象中
✅ 代码可读性好:people[0].name 比两个独立数组更直观
✅ 易于扩展:如果要添加地址、邮箱等信息,只需在结构体中添加字段
✅ 不易出错:不会出现两个数组索引不同步的问题
现在我们的数据结构清晰多了!
排序算法
为什么需要排序?
排序(Sorting)是指将一组未排序的值重新排列成有序序列的过程。
排序的重要性:
- ✅ 有序数据可以使用二分查找(𝑂(log n))
- ❌ 无序数据只能使用线性搜索(𝑂(n))
- 排序后搜索效率大大提升!
现实应用:
- 通讯录按姓名排序
- 商品按价格排序
- 搜索结果按相关性排序
事实上,存在多种不同的排序算法,它们的效率各不相同。
选择排序(Selection Sort)
核心思想
每次从未排序部分选择最小的元素,放到已排序部分的末尾。
形象比喻:就像从一堆扑克牌中,每次选出最小的一张,按顺序排成一排。
可视化示意

伪代码
For i from 0 to n–1
Find smallest number between numbers[i] and numbers[n-1]
Swap smallest number with numbers[i]
步骤说明:
- 在整个数组中找到最小值,与第1个位置交换
- 在剩余部分找到最小值,与第2个位置交换
- 重复这个过程,直到排序完成
时间复杂度分析
操作次数:
- 第1轮:检查
n-1个元素 - 第2轮:检查
n-2个元素 - …
- 最后一轮:检查
1个元素
总共:
(n-1) + (n-2) + (n-3) + ... + 1 = n(n-1)/2
化简:
n(n-1)/2 = (n² - n)/2 ≈ n²/2
忽略常数,得到:𝑂(n²)
选择排序的复杂度:
- 最坏情况:𝑂(n²) - 完全逆序
- 最好情况:Ω(n²) - 已经有序
- 特点:无论数据如何排列,都需要 n² 级别的比较!
冒泡排序(Bubble Sort)
核心思想
反复比较相邻的两个元素,如果顺序错误就交换它们,使较大的元素像”气泡”一样逐渐”冒”到数组末尾。
形象比喻:就像水中的气泡,大气泡逐渐上浮。
伪代码
Repeat n-1 times
For i from 0 to n–2
If numbers[i] and numbers[i+1] out of order
Swap them
If no swaps
Quit
步骤说明:
- 比较第1个和第2个元素,如果逆序就交换
- 比较第2个和第3个元素,如果逆序就交换
- …一直到数组末尾
- 重复这个过程
n-1次 - 优化:如果某一轮没有发生任何交换,说明已经有序,可以提前退出
示例
初始数组:[5, 2, 7, 4, 1]
第1轮:
- 比较 5 和 2 → 交换 →
[2, 5, 7, 4, 1] - 比较 5 和 7 → 不交换
- 比较 7 和 4 → 交换 →
[2, 5, 4, 7, 1] - 比较 7 和 1 → 交换 →
[2, 5, 4, 1, 7] - 结果:最大值 7 “冒泡”到了末尾!
第2轮:
- 只需处理前4个元素(7已经在正确位置)
- 最终 5 会”冒泡”到倒数第2个位置
…以此类推
时间复杂度分析
最坏情况(完全逆序):
第1轮:(n-1) 次比较
第2轮:(n-1) 次比较
...
第n-1轮:(n-1) 次比较
总计:(n-1) × (n-1) = n² - 2n + 1 ≈ n²
冒泡排序的复杂度:
- 最坏情况:𝑂(n²) - 完全逆序
- 最好情况:Ω(n) - 已经有序,只需一轮就发现没有交换,退出!
- 平均情况:𝑂(n²)
选择排序 vs 冒泡排序
| 特性 | 选择排序 | 冒泡排序 |
|---|---|---|
| 最好情况 | Ω(n²) | Ω(n) ✅ |
| 最坏情况 | 𝑂(n²) | 𝑂(n²) |
| 交换次数 | 少 | 多 |
| 能否提前结束 | ❌ | ✅ |
可视化工具:
你可以在这个网站查看排序算法的动画演示: 排序算法可视化
递归(Recursion)
如何提高排序效率?
前面介绍的选择排序和冒泡排序都是 𝑂(n²),对于大规模数据来说太慢了!
能不能更快?答案是:可以! 但需要一个新的编程技巧——递归。
什么是递归?
递归(Recursion)是指函数调用自身的编程技术。
递归的例子:二分查找
还记得之前的二分查找吗?它就是递归的:
If no doors left
Return false
If number behind middle door
Return true
Else if number < middle door
Search left half ← 递归调用自己!
Else if number > middle door
Search right half ← 递归调用自己!
关键特点:
Search left half和Search right half实际上是再次调用Search函数本身- 每次调用,问题规模都变小(从整个数组 → 一半数组 → 四分之一数组…)
- 最终问题小到可以直接解决(只剩1个元素或没有元素)
Week 0 的递归示例
还记得Week 0 的电话簿查找吗?也可以用递归实现:
原始版本(使用循环):
1 Pick up phone book
2 Open to middle of phone book
3 Look at page
4 If person is on page
5 Call person
6 Else if person is earlier in book
7 Open to middle of left half of book
8 Go back to line 3 ← 跳回去,形成循环
9 Else if person is later in book
10 Open to middle of right half of book
11 Go back to line 3 ← 跳回去,形成循环
12 Else
13 Quit
递归版本(更简洁):
1 Pick up phone book
2 Open to middle of phone book
3 Look at page
4 If person is on page
5 Call person
6 Else if person is earlier in book
7 Search left half of book ← 递归!调用自己
9 Else if person is later in book
10 Search right half of book ← 递归!调用自己
12 Else
13 Quit
区别:
- 原始版本:显式地 “go back to line 3”
- 递归版本:隐式地通过”调用自己”来重复过程
- 递归版本更简洁、更优雅!
递归示例:打印金字塔
回顾Week 1,我们要打印这样的金字塔:
#
##
###
####
方法1:使用循环(迭代)
// 使用迭代(循环)绘制金字塔
#include <cs50.h>
#include <stdio.h>
void draw(int n);
int main(void)
{
int height = get_int("Height: ");
draw(height);
}
void draw(int n)
{
// 外层循环:控制行数
for (int i = 0; i < n; i++)
{
// 内层循环:每行打印 i+1 个 #
for (int j = 0; j < i + 1; j++)
{
printf("#");
}
printf("\n");
}
}
工作原理:
- 第1行:打印 1 个 #
- 第2行:打印 2 个 #
- 第3行:打印 3 个 #
- …
- 第n行:打印 n 个 #
方法2:使用递归
// 使用递归绘制金字塔
#include <cs50.h>
#include <stdio.h>
void draw(int n);
int main(void)
{
int height = get_int("Height: ");
draw(height);
}
void draw(int n)
{
// 基础情况(base case):停止递归
if (n <= 0)
{
return;
}
// 递归步骤1:先画高度为 n-1 的金字塔
draw(n - 1);
// 递归步骤2:再画第 n 行(n 个 #)
for (int i = 0; i < n; i++)
{
printf("#");
}
printf("\n");
}
递归工作原理(以 draw(4) 为例):
draw(4)
├─ draw(3) ← 先画高度3的金字塔
│ ├─ draw(2) ← 先画高度2的金字塔
│ │ ├─ draw(1) ← 先画高度1的金字塔
│ │ │ ├─ draw(0) ← 基础情况,直接返回
│ │ │ └─ 打印 #
│ │ └─ 打印 ##
│ └─ 打印 ###
└─ 打印 ####
关键概念:
- 基础情况(Base Case):
if (n <= 0) { return; }- 这是递归的终止条件
- 没有基础情况,递归会无限进行,导致栈溢出!
- 递归步骤(Recursive Case):
draw(n - 1); // 调用自己,但问题规模变小了- 每次递归,
n都减1 - 问题逐渐变小,最终达到基础情况
- 每次递归,
- 执行顺序:
- 先递归到最底层(
draw(0)) - 然后逐层返回,打印每一行
- 就像”先下到谷底,再一层层爬上来”
- 先递归到最底层(
递归的思维方式:
- ❌ 不要想”计算机怎么一步步执行”
- ✅ 要想”如何把大问题分解成小问题”
- 金字塔(4) = 金字塔(3) + 第4行
- 金字塔(3) = 金字塔(2) + 第3行
- …直到 金字塔(0) = 什么都不做
归并排序(Merge Sort)
现在我们可以利用递归来实现一种非常高效的排序算法——归并排序!
核心思想
分治法(Divide and Conquer):
- 分(Divide):把数组分成两半
- 治(Conquer):递归地排序两半
- 合(Merge):合并两个已排序的数组
伪代码
If only one number
Quit ← 基础情况
Else
Sort left half ← 递归!
Sort right half ← 递归!
Merge sorted halves
详细示例
初始数组:[6, 3, 4, 1]
第1步:分割
[6, 3, 4, 1]
询问:"只有一个数吗?" → 不是,继续分割
分成两半:
[6, 3] | [4, 1]
第2步:递归处理左半部分
[6, 3] | [4, 1]
处理左半部分 [6, 3]:
询问:"只有一个数吗?" → 不是
继续分割:
[6] | [3]
询问:"[6] 只有一个数吗?" → 是!返回 [6]
询问:"[3] 只有一个数吗?" → 是!返回 [3]
合并 [6] 和 [3]:
→ [3, 6] ✓ 左半部分已排序!
第3步:递归处理右半部分
[3, 6] | [4, 1]
处理右半部分 [4, 1](同样的过程):
分割成 [4] | [1]
合并成 [1, 4] ✓ 右半部分已排序!
现在有:
[3, 6] | [1, 4]
第4步:合并两个已排序的数组
合并 [3, 6] 和 [1, 4]:
比较:3 vs 1 → 选 1
比较:3 vs 4 → 选 3
比较:6 vs 4 → 选 4
剩下:6
最终结果:[1, 3, 4, 6] ✓ 完成!
可视化树形结构
[6, 3, 4, 1] 原始数组
/ \
[6, 3] [4, 1] 分割
/ \ / \
[6] [3] [4] [1] 分割到单个元素
\ / \ /
[3, 6] [1, 4] 合并
\ /
[1, 3, 4, 6] 最终合并
时间复杂度分析
分割阶段
数组大小从 n → n/2 → n/4 → … → 1
需要 log₂(n) 层
合并阶段
每一层都需要处理 n 个元素
总复杂度
层数 × 每层的工作量 = log(n) × n = n log(n)
归并排序的复杂度:
- 最坏情况:𝑂(n log n)
- 最好情况:Ω(n log n)
- 平均情况:Θ(n log n)
特点:无论数据如何排列,都是 n log n!
对比总结
| 算法 | 最好情况 | 最坏情况 | 稳定性 |
|---|---|---|---|
| 选择排序 | Ω(n²) | 𝑂(n²) | 不稳定 |
| 冒泡排序 | Ω(n) | 𝑂(n²) | 稳定 |
| 归并排序 | Ω(n log n) | 𝑂(n log n) | 稳定 |
归并排序的优势:
- ✅ 效率高且稳定
- ✅ 最坏情况也是 n log n
- ❌ 需要额外的内存空间(用于合并)
可视化资源
强烈推荐观看这个视频,直观理解各种排序算法:
视频演示了:
- Selection Sort(选择排序)
- Shell Sort(希尔排序)
- Insertion Sort(插入排序)
- Merge Sort(归并排序)
- Quick Sort(快速排序)
- Heap Sort(堆排序)
- Bubble Sort(冒泡排序)
- Comb Sort(梳排序)
- Cocktail Sort(鸡尾酒排序)
- …等等
小知识:Cocktail Sort(鸡尾酒排序)是冒泡排序的变种,双向进行冒泡!
总结
本周我们深入学习了算法的设计与分析,这是计算机科学的核心内容。
核心知识点
1. 搜索算法
| 算法 | 复杂度 | 前提条件 | 特点 |
|---|---|---|---|
| 线性搜索 | 𝑂(n) | 无 | 简单但慢 |
| 二分查找 | 𝑂(log n) | 数组已排序 | 快速高效 |
2. 排序算法
| 算法 | 最好情况 | 最坏情况 | 空间 |
|---|---|---|---|
| 选择排序 | Ω(n²) | 𝑂(n²) | 𝑂(1) |
| 冒泡排序 | Ω(n) | 𝑂(n²) | 𝑂(1) |
| 归并排序 | Ω(n log n) | 𝑂(n log n) | 𝑂(n) |
3. 算法复杂度
大O表示法用于表示算法的效率:
- 𝑂 - 上界(最坏情况)
- Ω - 下界(最好情况)
- Θ - 严格界限(上下界相同)
常见复杂度(从快到慢):
𝑂(1) < 𝑂(log n) < 𝑂(n) < 𝑂(n log n) < 𝑂(n²) < 𝑂(2ⁿ)
4. 递归
递归是函数调用自身的技术:
- 必须有基础情况(终止条件)
- 必须向基础情况逐渐靠近
- 适合解决可以分解成相似子问题的任务
5. 结构体(Structs)
使用 struct 创建自定义数据类型:
typedef struct {
string name;
string number;
} person;
实践技能
✅ 能够分析算法的时间复杂度
✅ 能够选择合适的搜索和排序算法
✅ 理解递归的工作原理
✅ 能够使用结构体组织复杂数据
下周预告
下周我们将学习内存(Memory),深入理解:
- 指针
- 内存管理
- 数据结构的底层实现
这将帮助你更深刻地理解计算机是如何工作的!
参考资料:
下次见! 🚀