CS50 Week 2: 数组(Arrays)
编译过程详解
上节提到过,编译就是把源码翻译为机器码。让我们以上节的hello.c为例,深入了解编译的四个阶段:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string name = get_string("What's your name? ");
printf("hello, %s\n", name);
}
编译命令
在终端输入以下命令对hello.c进行编译:
clang -o hello hello.c -lcs50
参数说明:
clang- C语言编译器(C Language)-o hello- 指定输出文件名为hello(output)hello.c- 源代码文件-lcs50- 链接CS50库(link library)
使用make简化编译:
上节课我们使用make hello,它会自动调用clang并添加必要的参数,生成可执行文件。CS50的VS Code环境已经配置好了make命令,所以我们通常直接用make即可。
前面介绍clang的具体用法,只是为了让你理解编译的底层过程。
编译的四个阶段
编译实际上包含以下四个步骤:
1. 预处理(Preprocessing)
作用:处理所有以#开头的预处理指令
- 将头文件(如
stdio.h、cs50.h)的内容复制到源代码中 - 处理宏定义(
#define) - 处理条件编译(
#ifdef、#ifndef等)
结果:生成一个展开了所有头文件和宏的C源代码文件
2. 编译(Compiling)
作用:将C源代码翻译成汇编语言(Assembly Language)
汇编代码示例:
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movabsq $.L.str, %rsi
callq get_string
movq %rax, -8(%rbp)
movabsq $.L.str.1, %rdi
movq -8(%rbp), %rsi
callq printf
说明:这是人类相对可读的低级语言,每条指令对应CPU的一个操作。你现在不需要理解这些汇编指令的具体含义,只需知道它是源码和机器码之间的中间形式。
3. 汇编(Assembling)
作用:将汇编代码转换为机器码(二进制代码)
机器码示例(二进制):
01111111010001010100110001000110
00000010000000010000000100000000
00000000000000000000000000000000
00000001000000000011111000000000
...
说明:这些0和1就是CPU真正能执行的指令,也称为目标代码(object code)。
4. 链接(Linking)
作用:将多个目标代码文件和库文件合并成一个可执行文件
- 你的代码的机器码
- 标准库(如
printf函数)的机器码 - CS50库(如
get_string函数)的机器码
结果:生成最终的可执行文件(如hello)
小结
源代码(.c) → [预处理] → 展开的源代码 → [编译] → 汇编代码(.s)
→ [汇编] → 目标代码(.o) → [链接] → 可执行文件
作为初学者,你不需要完全理解这些细节。只需记住:
make帮我们自动完成了这四个步骤- 编译器把人类可读的代码转换成计算机可执行的二进制代码
调试(Debugging)
程序是人写的,就难免会出现bug(错误)。调试(debugging)就是找到并修正bug的过程。
调试的常用方法:
- printf调试:在代码中插入
printf语句,打印变量值来追踪程序执行 - 调试器(Debugger):使用VS Code的调试工具,可以设置断点、单步执行
- 橡皮鸭调试法:向别人(或橡皮鸭)解释你的代码,往往能发现问题
- 分而治之:注释掉部分代码,逐步缩小bug的范围
关于调试的具体技巧,我们会在后续的实践中详细学习。
下面进入本周的主题:数组(Arrays)
数组
数据类型的内存大小
上周我们讨论了各种数据类型,让我们回顾一下它们各自占用的内存大小:
| 数据类型 | 占用字节数 | 说明 |
|———|———–|——|
| bool | 1 byte | 布尔类型 |
| char | 1 byte | 单个字符 |
| int | 4 bytes | 整数 |
| long | 8 bytes | 长整数 |
| float | 4 bytes | 单精度浮点数 |
| double | 8 bytes | 双精度浮点数 |
| string | ? bytes | 字符串(长度可变) |
重要概念:
- 计算机的内存是有限的,所以可表示的数据大小也是有限的
- 不同类型的数据在内存中占用不同的空间
string的大小取决于字符串的长度(每个字符1字节,加上结尾的\0)
内存存储示意:
你可以想象内存就像一排连续的盒子,每个盒子是1字节:
- 一个
char占用1个盒子 - 一个
int占用4个盒子(连续的) - 一个
long占用8个盒子

数组的概念
让我们通过一个实际例子来理解数组:
#include <stdio.h>
int main(void)
{
// Scores
int score1 = 72;
int score2 = 73;
int score3 = 33;
printf("Average is %f:\n ", (score1 + score2 + score3) / 3.0);
}
注意:
(score1 + score2 + score3) / 3.0中除以3.0而不是3- 这涉及隐式类型转换:当整数和浮点数运算时,结果会转换为浮点数
- 如果写成
/ 3,结果会被截断为整数
问题:代码重复
上面的代码有个问题:如果要存储100个分数呢?定义100个变量?这显然不现实!
解决方案:数组
数组(Array)就是内存中连续存储的一组相同类型的数据。
想象一下,score1、score2、score3在内存中是这样存储的:

它们是分散的独立变量。而数组可以把它们组织成一个整体:
scores数组在内存中:
[72] [73] [33]
↑ ↑ ↑
[0] [1] [2] ← 索引
定义数组:int scores[3] 告诉编译器:
- 在内存中分配连续的3个
int类型的存储空间 - 数组名是
scores - 可以存储3个整数
让我们用数组改写上面的代码:
int main(void)
{
// Scores
int scores[3];
scores[0] = 72;
scores[1] = 73;
scores[2] = 33;
// Print average
printf("Average: %f\n", (scores[0] + scores[1] + scores[2]) / 3.0);
}
重要概念:
- 数组索引从0开始:这是C语言(以及大多数编程语言)的约定
scores[0]是数组的第1个元素(值为72)scores[1]是数组的第2个元素(值为73)scores[2]是数组的第3个元素(值为33)
访问数组元素:使用方括号[]和索引:
scores[0] = 72; // 给第1个元素赋值
int x = scores[1]; // 读取第2个元素的值
使用循环优化数组操作
上面的代码虽然展示了数组的基本用法,但还可以进一步优化:
#include <stdio.h>
#include <cs50.h>
int main(void)
{
// Scores
int scores[3];
for (int i = 0; i < 3; i++)
{
scores[i] = get_int("Score: ");
}
printf("Average is: %f\n ", (scores[0] + scores[1] + scores[2]) / 3.0);
}
改进:
- 使用for循环遍历数组,避免重复代码
- 数组元素的值由用户输入,更加灵活
- 循环变量
i从0到2,正好对应数组的3个索引
使用函数进一步抽象
利用上节课讲的函数抽象,我们可以将”计算平均值”这个功能提取出来:
int const N = 3;
float average(int, int[]);
int main(void)
{
int scores[N];
for (int i = 0; i < N; i++)
{
scores[i] = get_int("Score: ");
}
printf("Average: %f\n", average(N,scores));
}
float average(int length, int scores[])
{
int sum = 0;
for (int i = 0; i < length; i++)
{
sum += scores[i];
}
return sum / (float)length;
}
重要知识点:
const int N = 3;定义常量Nfloat average(int, int[]);是函数声明- 函数
average接受两个参数:数组长度(int)和数组本身(int[]) return sum / (float)length;中的(float)是强制类型转换,确保结果是浮点数
传递数组给函数:
- 在C语言中,数组作为参数传递时,实际传递的是数组的内存地址
- 因此需要额外传递数组长度,函数才知道数组有多大
字符串
核心概念:字符串本质上就是一个字符数组(array of characters)。
下面代码演示如何定义字符和字符串
int main(void)
{
char c1 = 'H';
char c2 = 'I';
char c3 = '!';
printf("%c%c%c\n", c1,c2,c3);
}
输出:HI!
格式占位符:
%c输出字符型(character)%i输出整型(integer)
如果我们用%i来打印字符,会输出什么呢?
printf("%i %i %i\n", c1, c2, c3);
输出:72 73 33
这些是字符的ASCII码:
- ‘H’ 的ASCII码是 72
- ‘I’ 的ASCII码是 73
- ’!’ 的ASCII码是 33
字符串的结束符:
在内存中,字符串实际上是这样存储的:
['H'] ['I'] ['!'] ['\0']
72 73 33 0
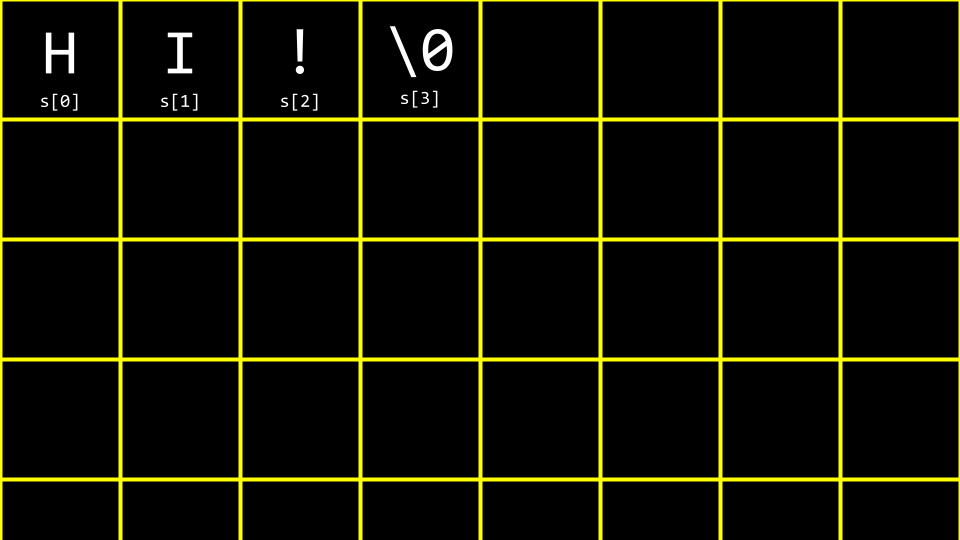
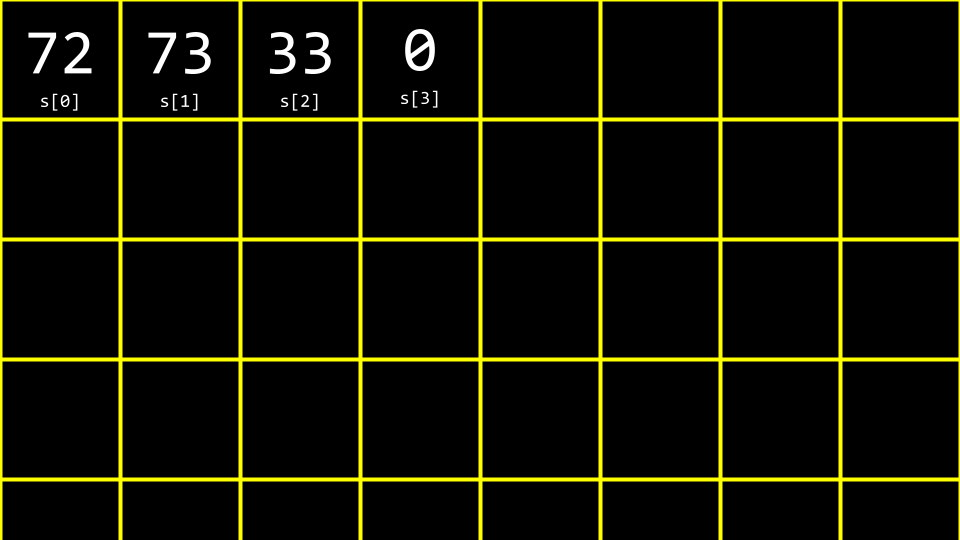
\0(读作”null terminator”或”空终止符”)标记字符串的结束,它的ASCII码是0。这个结束符是自动添加的,所以字符串”HI!”实际占用4个字节。
字符串就是字符数组
为了更好理解string的本质,让我们用数组的方式访问字符串:
#include <stdio.h>
#include <cs50.h>
int main(void)
{
string s1 = "HI!";
printf("%i %i %i\n", s1[0], s1[1], s1[2]);
}
输出:72 73 33
说明:
s1[0]访问字符串的第1个字符 ‘H’(ASCII 72)s1[1]访问字符串的第2个字符 ‘I’(ASCII 73)s1[2]访问字符串的第3个字符 ‘!’(ASCII 33)
让我们也打印出隐藏的结束符\0:
#include <stdio.h>
#include <cs50.h>
int main(void)
{
string s1 = "HI!";
printf("%i %i %i %i\n", s1[0], s1[1], s1[2], s1[3]);
}
输出:72 73 33 0
重要发现:
s1[3]的值是0,这就是字符串结束符\0的ASCII码- 如果用
%c打印s1[3],不会显示任何可见字符(因为它是空字符) \0让程序知道字符串到哪里结束
继续修改代码如下int main(void) { string s = "HI!"; string t = "BYE!"; printf("%s\n", s); printf("%s\n", t); }
这段程序定义了两个字符串,在内存中它们是这样存储的:
s: ['H']['I']['!']['\0']
t: ['B']['Y']['E']['!']['\0']
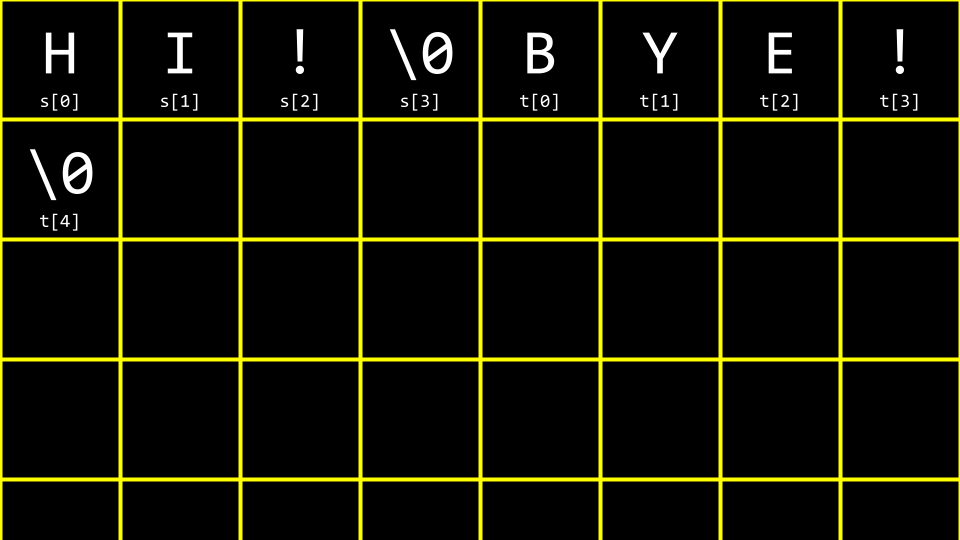
字符串数组
我们也可以创建一个字符串数组,即数组的每个元素都是一个字符串:
int main(void)
{
string words[2];
words[0] = "HI!";
words[1] = "BYE!";
printf("%s\n", words[0]);
printf("%s\n", words[1]);
}
理解字符串数组:
words[0]是第1个字符串 “HI!”words[1]是第2个字符串 “BYE!”
二维数组访问
我们可以像访问二维数组一样访问字符串数组中的每个字符:
#include <stdio.h>
#include <cs50.h>
int main(void)
{
string words[2];
words[0] = "HI!";
words[1] = "BYE!";
// 逐个打印第1个字符串的字符
printf("%c%c%c\n", words[0][0], words[0][1], words[0][2]);
// 逐个打印第2个字符串的字符
printf("%c%c%c%c\n", words[1][0], words[1][1], words[1][2], words[1][3]);
}
输出:
HI!
BYE!
二维索引:
words[0][0]- 第1个字符串的第1个字符 ‘H’words[0][1]- 第1个字符串的第2个字符 ‘I’words[1][2]- 第2个字符串的第3个字符 ‘E’
可以理解为一个二维字符数组:
words:
[0] → ['H']['I']['!']['\0']
[1] → ['B']['Y']['E']['!']['\0']
字符串长度
获取字符串长度是编程中的常见需求。在C语言中,由于字符串是字符数组,我们需要找到结束符\0的位置来确定长度。
手动实现字符串长度计算
#include <stdio.h>
#include <cs50.h>
int main(void)
{
string name = get_string("Name: ");
// Count number of characters up until '\0' (aka NUL)
int n = 0;
while (name[n] != '\0')
{
n++;
}
printf("string length is: %i\n", n);
}
工作原理:
- 从索引0开始,逐个检查字符
- 当遇到
\0时停止计数 - 返回计数值,即字符串长度
函数抽象
将计算字符串长度的功能抽象为一个函数:
#include <stdio.h>
#include <cs50.h>
int string_length(string s);
int main(void)
{
string name = get_string("Name: ");
int length = string_length(name);
printf("Name length: %i\n", length);
}
int string_length(string s)
{
int n = 0;
while (s[n] != '\0')
{
n++;
}
return n;
}
使用标准库函数 strlen
由于计算字符串长度是常用功能,C语言的标准库string.h已经提供了strlen函数:
#include <string.h>
int main(void)
{
string name = get_string("Name: ");
int length = strlen(name);
printf("Name length: %i\n", length);
}
优势:
strlen是经过优化的标准实现,效率更高- 不需要自己实现,减少代码量和出错机会
- 其他程序员看代码时能立即理解你的意图
注意:strlen返回类型是size_t,但在本课程中可以将其赋值给int。
字符串处理:大小写转换
ctype.h是另一个非常有用的C标准库,提供了许多字符处理函数。
任务:将字符串转为大写
让我们实现一个程序,将用户输入的字符串全部转换为大写。
方法1:手动实现
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0; i < strlen(s); i++)
{
if (s[i] >= 'a' && s[i] <= 'z')
{
printf("%c", s[i]-32);
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}
工作原理:
- 遍历字符串的每个字符
- 如果字符是小写字母(’a’ 到 ‘z’),减去32得到对应的大写字母
- 为什么是32?因为在ASCII表中,大写字母和小写字母相差32
- ‘A’ = 65, ‘a’ = 97, 差值 = 32
- ‘Z’ = 90, ‘z’ = 122, 差值 = 32
方法2:使用标准库函数
使用ctype.h库提供的函数可以更优雅地实现:
#include <stdio.h>
#include <cs50.h>
#include <string.h>
#include <ctype.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0; i < strlen(s); i++)
{
if (islower(s[i]))
{
printf("%c", toupper(s[i]));
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}
ctype.h提供的函数:
islower(c)- 判断字符c是否为小写字母isupper(c)- 判断字符c是否为大写字母toupper(c)- 将字符c转为大写(如果是小写的话)tolower(c)- 将字符c转为小写(如果是大写的话)
进一步优化:
实际上,toupper函数会自动判断字符是否为小写,如果不是就原样返回,因此可以简化代码:
#include <stdio.h>
#include <cs50.h>
#include <string.h>
#include <ctype.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0; i < strlen(s); i++)
{
printf("%c", toupper(s[i]));
}
printf("\n");
}
说明:
toupper函数智能处理:如果字符是小写,转为大写;否则原样返回- 代码更简洁,不需要手动判断
islower
性能提示:
上面的代码在循环条件中调用strlen(s),这意味着每次循环都会重新计算字符串长度。更高效的写法是:
int length = strlen(s);
for (int i = 0; i < length; i++)
{
printf("%c", toupper(s[i]));
}
参考资料:更多关于ctype库的用法,可以查询 CS50 Manual - ctype.h
命令行参数
命令行参数(Command-Line Arguments)是指在运行程序时,通过命令行传递给程序的额外信息。
什么是命令行参数?
你已经使用过命令行参数了!例如:
clang -o hello hello.c -lcs50
这里:
clang是程序名-o hello、hello.c、-lcs50都是命令行参数
其他例子:
ls -l # -l 是参数
rm file.txt # file.txt 是参数
在自己的程序中使用命令行参数
让我们先看一个不使用命令行参数的程序:
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string answer = get_string("What's your name? ");
printf("hello, %s\n", answer);
}
这段代码需要用户运行时输入名字,比较麻烦。如果能在运行程序时直接提供名字就更方便了!
使用命令行参数改进程序
#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[])
{
if (argc == 2)
{
printf("Hello, %s\n", argv[1]);
}
else
{
printf("Hello, World\n");
}
}
运行示例:
./greet David
输出:Hello, David
./greet
输出:Hello, World
main函数的参数详解
注意main函数现在接受两个参数:
int main(int argc, string argv[])
int argc- Argument Count(参数数量)- 表示命令行参数的数量(包括程序名本身)
- 最小值是1(只有程序名)
string argv[]- Argument Vector(参数向量/数组)- 一个字符串数组,存储所有命令行参数
argv[0]总是程序名本身argv[1]是第一个用户提供的参数argv[2]是第二个用户提供的参数- …依此类推
示例分析:
./greet David
此时:
argc = 2(两个参数:程序名 + David)argv[0] = "./greet"(程序名)argv[1] = "David"(用户输入的参数)
./greet David Emma
此时:
argc = 3argv[0] = "./greet"argv[1] = "David"argv[2] = "Emma"退出状态码
当程序结束时,会向操作系统返回一个退出状态码(Exit Status Code):
0- 表示程序正常执行,没有错误- 非零值(通常是
1)- 表示程序执行过程中发生了错误
使用退出状态码
让我们改进前面的程序,加入错误处理:
#include <stdio.h>
#include <cs50.h>
int main(int argc, string argv[])
{
if (argc != 2)
{
printf("Usage: ./greet NAME\n");
return 1; // 返回1表示错误
}
printf("Hello, %s\n", argv[1]);
return 0; // 返回0表示成功
}
运行示例:
./greet
Usage: ./greet NAME
在Linux/Mac系统中,可以使用echo $?查看上一个程序的退出状态码:
./greet David
Hello, David
echo $?
0 # 成功
./greet
Usage: ./greet NAME
echo $?
1 # 失败
为什么需要退出状态码?
- 让其他程序知道你的程序是否成功执行
- 在Shell脚本中,可以根据退出状态码决定下一步操作
- 方便调试和错误追踪
最佳实践:
- 总是在main函数中返回适当的退出状态码
return 0;表示成功(实际上,如果不写,C99标准会自动返回0)return 1;(或其他非零值)表示不同类型的错误
密码学简介
密码学(Cryptography)是对信息进行加密和解密的技术。
基本概念
明文(Plaintext) + 密钥(Key) → [加密算法] → 密文(Ciphertext)
密文(Ciphertext) + 密钥(Key) → [解密算法] → 明文(Plaintext)
术语解释:
- 明文:原始的、可读的信息
- 密文:加密后的、不可读的信息
- 密钥:用于加密和解密的特殊参数
- 加密算法:将明文转换为密文的规则
简单示例:凯撒密码
凯撒密码(Caesar Cipher)是最简单的加密方法之一,它将每个字母向后移动固定位数:
明文: HELLO
密钥: 3(向后移3位)
密文: KHOOR
H → K (H+3)
E → H (E+3)
L → O (L+3)
L → O (L+3)
O → R (O+3)
与本周学习的联系
现在我们已经学会了:
- ✓ 字符和字符数组(字符串)
- ✓ 遍历字符串的每个字符
- ✓ ASCII码的操作
- ✓ 命令行参数(可以作为密钥)
这些都是实现密码学算法的基础!本周的Problem Set你将实现一个加密程序。
总结
本周我们深入学习了C语言的数组和字符串,主要内容包括:
核心知识点
1. 编译过程
- 四个阶段:预处理 → 编译 → 汇编 → 链接
- 理解源代码如何转换为可执行文件
make工具简化编译过程
2. 数组(Arrays)
- 数组是连续存储的相同类型数据的集合
- 数组索引从0开始
- 定义格式:
类型 数组名[大小] - 访问元素:
数组名[索引]
3. 字符串(Strings)
- 字符串本质是字符数组
- 字符串以
\0(null terminator)结尾 - 可以像数组一样访问字符串的每个字符
- ASCII码:字符与数字的对应关系
4. 常用库函数
string.h:strlen()- 获取字符串长度ctype.h:toupper()、tolower()、islower()、isupper()- 字符处理
5. 命令行参数
int argc- 参数数量string argv[]- 参数数组argv[0]总是程序名- 退出状态码:0表示成功,非零表示错误
6. 调试技巧
- printf调试法
- 使用调试器
- 橡皮鸭调试法
编程技巧
- 使用循环处理数组:避免重复代码
- 函数抽象:将常用功能封装成函数
- 使用标准库:优先使用成熟的库函数
- 错误处理:检查用户输入,返回适当的退出状态码
- 性能优化:避免在循环中重复计算(如strlen)
下一步
下周我们将学习算法(Algorithms),包括排序和搜索算法,这将帮助你理解如何高效地处理数据。
参考资料: